6.5 正则表达式的语法规则
PHP支持两种正则表达式的语法,一种是POSIX,一种是Perl的PCRE,这两种都集成于PHP的默认库中。这两种语法相比而言,POSIX比较快,而PCRE拥有二进制安全性。以下介绍POSIX语法。
最简单的正则表达式其实就是一个匹配操作,例如在name中找到n或am。
6.5.1 方括号([ ])
方括号内的一串字符是将要用来进行匹配的字符。
例如,正则表达式在方括号内的[name]是指在目标字符串中寻找字母n、a、m、e,[jk]表示在目标字符串中寻找字符j和k。
6.5.2 连字符(-)
但是很多情况下,不可能逐个列出所有字符。例如,需要匹配所有英文字符,则把26个英文字母全部输入,十分困难。这样就有如下表示。
•[a-z]表示匹配英文小写从a到z的任意字符。
•[A-Z]表示匹配英文大写从A到Z的任意字符。
•[A-Za-z]表示匹配英文大小写从大写A到小写z的任意字符。
•[0-9]表示匹配从0到9的任意十进制数。
由于字母和数字的区间固定,所以根据这样的表示方法[开始-结束],程序员可以重新定义区间大小,如,[2-7]、[c-f]等。
6.5.3 点号字符(.)
点号字符在正则表达式中是一个通配符。它代表所有字符和数字。例如,“.er”表示所有以er结尾的三个字符的字符串,它可以是per、ser、ter、@er、&er等。
6.5.4 限定符(+*?{n,m})
加号“+”表示其前面的字符至少一个。例如,“9+”表示目标字符串包含至少一个9。
星号“*”表示其前面的字符不止一个或0。例如,“y*”表示目标字符串包含0或不止一个y。
问号“?”表示其前面的字符一个或0。例如,“y?”表示目标字符串包含0或一个y。
大括号“{n,m}”表示其前面的字符有n或m个。例如,“a{3,5}”表示目标字符串包含3个或5个a。“a{3}”表示目标字符串包含3个a。“a{3,}”表示目标字符串包含至少3个a。
点号和星号一起使用,表示广义同配。“.*”表示匹配任意字符。
6.5.5 行定位符(^和$)
行定位符是用来确定匹配字符串所要出现的位置。
如果是在目标字符串开头出现,则使用符号“^”;如果是在目标字符串结尾出现则使用符号“$”。例如,^xiaoming是指“xiaoming”只能出现在目标字符串开头。8895$是指“8895”只能出现在目标字符串结尾。
有一个特殊表示,同时使用^$两个符号,就是“^[a-z]$”,表示目标字符串要只包含从a到z的单个字符。
6.5.6 排除字符([^])
符号“^”在方括号内所代表的意义则完全不同。它表示一个逻辑“否”。排除匹配字符串在目标字符串中出现的可能。例如,[^0-9]表示目标字符串包含从0到9以外的任意其他字符。
6.5.7 括号字符(( ))
括号字符表示子串,对包含在子串内字符的所有操作,都是以子串为整体进行的。也是把正则表达式分成不同部分的操作符。
6.5.8 选择字符(|)
选择字符表示“或”选择。例如,“com|cn|com.cn|net”表示目标字符串包含com或cn或com.cn或net。
6.5.9 转义字符与反斜杠(\)
由于“\”在正则表达式中属于特殊字符,如果单独使用此字符,则直接表示为作为特殊字符的转义字符。如果要表示反斜杠字符本身,则在此字符前添加转义字符“\”,为“\\”。
6.5.10 认证email的正则表达
在处理表单数据的时候,对用户的email进行认证是十分常用的。如何判断用户输入的是一个email地址呢?就是用正则表达式匹配。它的格式是什么样的呢?格式如下。
^[A-Za-z0-9_.]+@[ A-Za-z0-9_]+\.[ A-Za-z0-9.]+$
•^[A-Za-z0-9_.]+表示至少有一个英文大小写字符、数字、下划线、点号,或者这些字符的组合。
•@表示email中的“@”。
•[ A-Za-z0-9_]+表示至少有一个英文大小写字符、数字、下划线,或者这些字符的组合。
•\.表示email中“.com”之类的点。由于这里点号只是点本身,所以用反斜杠对它进行转义。
•[ A-Za-z0-9.]+$表示,至少有一个英文大小写字符、数字、点号,或者这些字符的组合,并且直到这个字符串的末尾。
6.5.11 使用正则表达式对字符串进行匹配
使用正则表达式对目标字符串进行匹配是学习正则表达式的主要功能。
完成这个操作需要使用到ereg()和eregi()函数。这两个函数都是在目标字符串中寻找符合特定正则表达规范的字符串子串。如果找到此子串,函数将会把它存储在一个数组中。
其中ereg()函数是对字符大小写不敏感,而eregi()函数是对字符大小写敏感的。它的格式如下:
ereg(正则表达规范,目标字符串,数组)
以下例子介绍利用正则表达规范匹配email输入的方法和技巧。
【例6.11】(实例文件:ch06\6.11.php)
<HTML>
<HEAD><meta http-equiv="Content-Type" content="text/html; charset=gb2312" /></HEAD>
<BODY>
<?php
$email = "wangxioaming2011@hotmail.com";
$email2 = "The email is liuxiaoshuai_2011@hotmail.com";
$asemail = "This is wangxioaming2011@hotmail";
$regex = '^[a-zA-Z0-9_.]+@[a-zA-Z0-9_]+\.[a-zA-Z0-9.]+$';
$regex2 = '[a-zA-Z0-9_.]+@[a-zA-Z0-9_]+\.[a-zA-Z0-9.]+$';
if(ereg($regex, $email, $a)){
echo "This is an email.";
print_r($a);
echo "<br />";
}
if(ereg($regex2, $email2, $b)){
echo "This is a new email.";
print_r($b);
echo "<br />";
}
if(ereg($regex, $asemail)){
echo "This is an email.";
}else{
echo "This is not an email.";
}
?>
</BODY>
</HTML>
运行结果如图6-11所示。
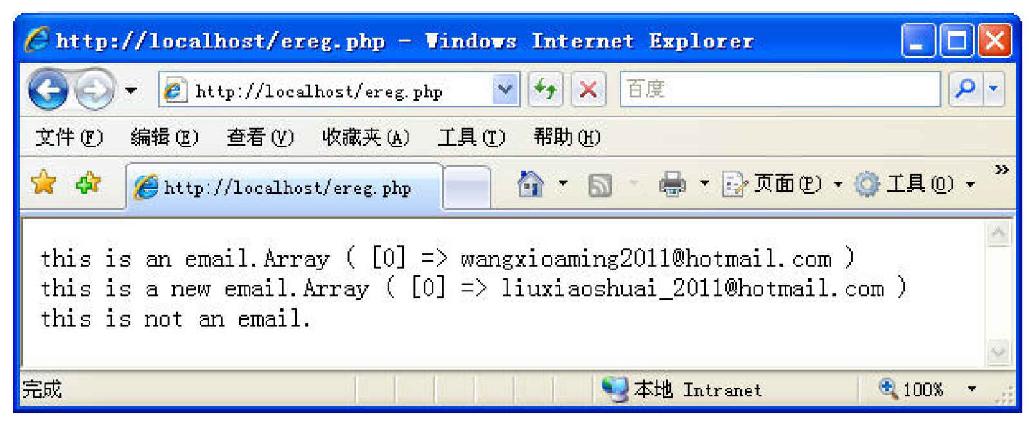
图6-11 程序运行结果
【案例分析】
(1)$email就是一个完整的email字符串,用$regex这个正则规范,也就是匹配email的规范来匹配$email。得出的结果为图6-11中第一行输出。
(2)由于ereg()函数的格式,ereg($regex, $email, $a)把匹配的子串存储在名为$a的数组中。print_r($a)打印数组的第一行。
(3)$email2就是一个包含了完整email的字符串。用$regex匹配,其返回值必然为false。用$regex2规范匹配,其返回值为真。因为$regex2规范中去掉了表示从字符串头部开始的符号“^”。ereg($regex2, $email2, $b)把匹配的子串存储在数组$b中。print_r($b)得到第二行数组的输出。
(4)$asemail字符串不符合规范$regex,返回值为false,得到相应输出。
6.5.12 使用正则表达式替换字符串子串
做好了字符串及其子串的匹配,如果需要对字符串的子串进行替换,也可以使用正则表达式完成。例如,把输入文本中的url换成可以直接点击的链接。此操作需要使用ereg_replace()和eregi_replace()函数。其中ereg_replace()对大小写敏感,而eregi_replace()对大小写不敏感。它们的格式为:
ereg_replace(正则表达规范,欲取代字符串子串,目标字符串)
以下例子介绍利用正则表达式取代字符串子串的方法和技巧。
【例6.12】(实例文件:ch06\6.12.php)
<HTML>
<HEAD><meta http-equiv="Content-Type" content="text/html; charset=gb2312" /></HEAD>
<BODY>
<?php
$searchurl = "这是搜索引擎连接:http://www.google.com/和http://www.baidu.com/。";
echo ereg_replace("(http://)([a-zA-Z0-9./-_]+)","<a href=\"\\0\">\\0</a>",$searchurl);
echo "<br />";
echo ereg_replace("(http://)([a-zA-Z0-9./-_]+)","<a href=\"\\0\">\\2</a>",$searchurl);
?>
</BODY>
</HTML>
运行结果如图6-12所示。
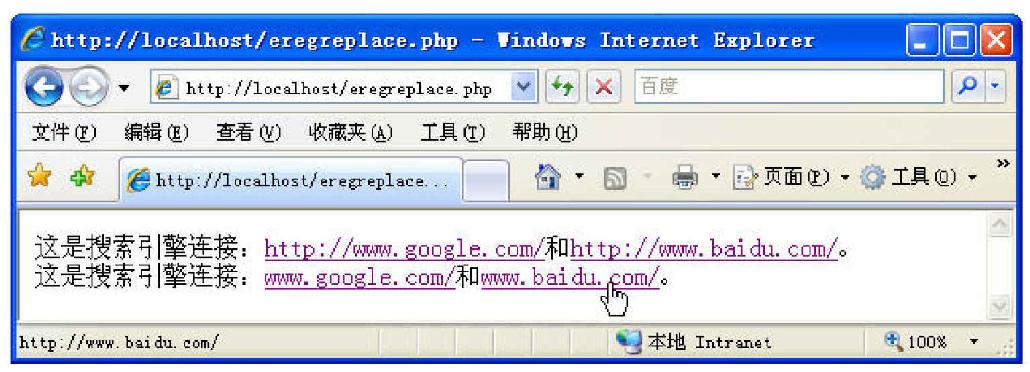
图6-12 程序运行结果
【案例分析】
(1)$searchurl里面包含两个url文本。ereg_replace()按照格式对$searchurl里的url进行匹配替换。
(2)正则规范为"(http://)([a-zA-Z0-9./-_]+)",分为两部分,(http://)和([a-zA-Z0-9./-_]+),前者直接匹配,后者用正则语法匹配。
(3)第一行的输出,替换为"<a href=\"\\0\">\\0</a>"。里面的“\\0”把反斜杠转义后表示的是“\0”,“\0”表示正则规则中所有部分匹配的内容。第二行的输出,替换为"<a href=\"\\0\">\\2</a>",里面的“\\2”把反斜杠转义后表示的是“\2”,“\2”表示正则规则中第二部分匹配的内容,输出如图。依次类推“\1”表示的是第一部分匹配的内容(http://)。
6.5.13 使用正则表达式切分字符串
使用正则表达式可以把目标字符串按照一定的正则规范切分成不同的子串。完成此操作要使用到split()和spliti()函数。其中split()为大小写敏感,spliti()为大小写不敏感。它的格式为:
split(正则表达式规范,目标字符串)
这个函数是指以正则规范内出现的字符为准,把目标字符串切分成若干个子串,并且存入数组。
以下例子介绍利用正则表达式取代字符串子串的方法和技巧。
【例6.13】(实例文件:ch06\6.13.php)
<HTML>
<HEAD><meta http-equiv="Content-Type" content="text/html; charset=gb2312" /></HEAD>
<BODY>
<?php
$someinput = "lilili2011@gmail.com\t李丽丽。";
$arr = split("@|\.|\t",$someinput);
print_r($arr);
?>
</BODY>
</HTML>
运行结果如图6-13所示。
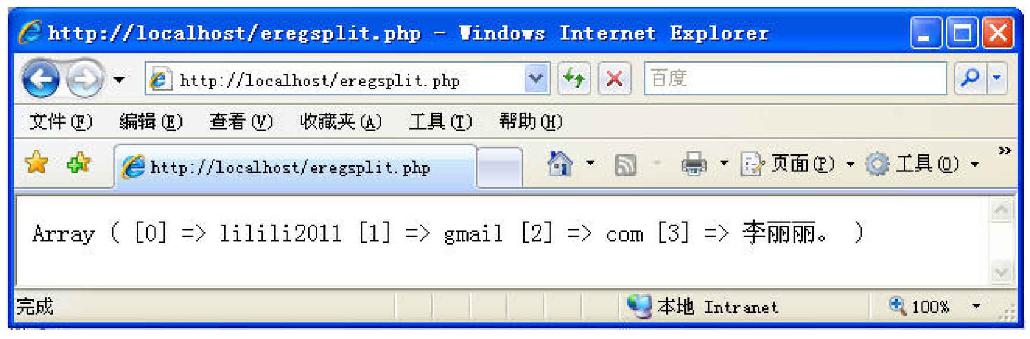
图6-13 程序运行结果
【案例分析】
(1)$someinput为包含多种字符的字符串。split()对其进行切分,并将结果存入数组$arr。
(2)其正则规范为"@|\.|\t",是指以“@”、“.”和Tab将字符串切分。