第16章 PHP与正则表达式
正则表达式其实就是与字符串匹配的一系列字符,或称为一个字符式样。PHP中支持两种类型的正则表达式:POSIX和Perl样式。每种类型都由一组函数来实现正则表达式。因为Perl比较流行也比较适合做匹配,所以本章详细介绍正则表达式的匹配和Perl样式的函数;主要包括的知识点有,掌握一般的匹配模式、熟记常用的元字符意义及一些匹配函数。
16.1 了解正则表达式
首先要了解什么是正则表达式。本节主要介绍正则表达式的概念,以及使用PHP做一个简单的正则验证。
16.1.1 什么是正则表达式
正则表达式是一个描述一组字符串的模板。正则表达式是使用多种操作符组合更小的表达式以构建类似算术表达式。
建立块的基本原则是正则表达式匹配一个单字符。多数字符,包括所有的字幕和数字,都是匹配它们自己的正则表达式。任何带有特殊含义的字符可以以反斜杠开头来进行引用。
在典型的搜索和替换操作中,必须提供要查找的确切文字。这种技术对于静态文本中的简单搜索和替换任务可能足够了,但是由于它缺乏灵活性,因此在搜索动态文本时就有困难了,甚至是不可能的。使用正则表达式,就可以:
- 测试字符串的某个模式。例如,可以对一个输入字符串进行测试,查看在该字符串中是否存在一个电话号码模式或一个信用卡号码模式。这称为数据有效性验证。
- 替换文本。可以在文档中使用一个正则表达式来标识特定文字,然后可以全部将其删除,或者替换为别的文字。
- 根据模式匹配从字符串中提取一个子字符串。可以用来在文本或输入字段中查找特定文字。
例如,如果需要搜索整个Web站点以删除某些过时的材料并替换某些HTML格式化标记,则可以使用正则表达式对每个文件进行测试,查看在该文件中是否存在所要查找的材料或HTML格式化标记。用这个方法,就可以将受影响的文件范围缩小到包含要删除或更改的材料的那些文件;然后可以使用正则表达式来删除过时的材料;最后,可以再次使用正则表达式来查找并替换那些需要替换的标记。
16.1.2 入门:一个简单的正则表达式
构造正则表达式的方法和创建数学表达式的方法一样,也就是用多种元字符与操作符将小的表达式结合在一起来创建更大的表达式。
可以通过在一对分隔符之间放入表达式模式的各种组件来构造一个正则表达式。对PHP而言,分隔符为一对正斜杠(/)字符。例如:
/cat/
以上就是一个简单的正则表达式。其组成元素可以是单个字符、字符集合、字符范围、字符间的选择或者所有这些组成元素的任意组合。
16.2 正则表达式的语法
在了解了正则表达式的基本情况以后,下面讲解正则表达式的语法。一个正则表达式是由普通字符(例如字符a到z)及特殊字符(称为元字符)组成的文字模式。该模式描述在查找文字主体时待匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
16.2.1 普通字符
普通字符由所有那些未显式指定为元字符的打印和非打印字符组成。这包括所有的大写和小写字母字符、所有数字、所有标点符号及一些符号。
最简单的正则表达式是一个单独的普通字符,可以匹配所搜索字符串中的该字符本身。例如,单字符模式“A”可以匹配所搜索字符串中任何位置出现的字母“A”。这里有一些单字符正则表达式模式的示例:
/O/ /r/ /z/
可以将多个单字符组合在一起得到一个较大的表达式。例如,下面的PHP就是通过组合单字符表达式“O”、“r”及“z”所创建出来的一个表达式。
/Orz/
请注意这里没有连接操作符。所需要做的就是将一个字符放在了另一个字符的后面。
16.2.2 特殊字符
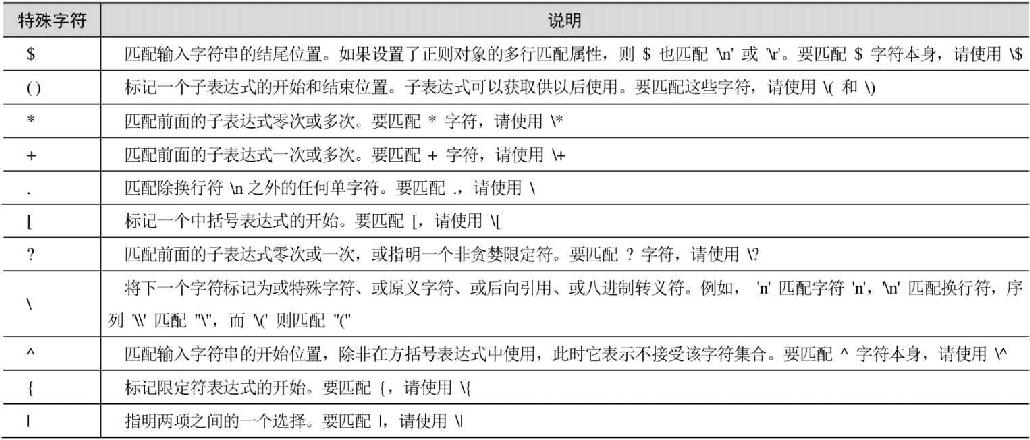
所谓特殊字符,就是一些有特殊含义的字符,比如说“*.txt”中的*,简单地说就是表示任何字符串的意思。有不少元字符在试图对其进行匹配时需要进行特殊的处理。要匹配这些特殊字符,必须首先将这些字符转义,也就是在前面使用一个反斜杠(\)。正则表达式有以下特殊字符,如表16.1所示。
表16.1 特殊字符表
16.2.3 非打印字符
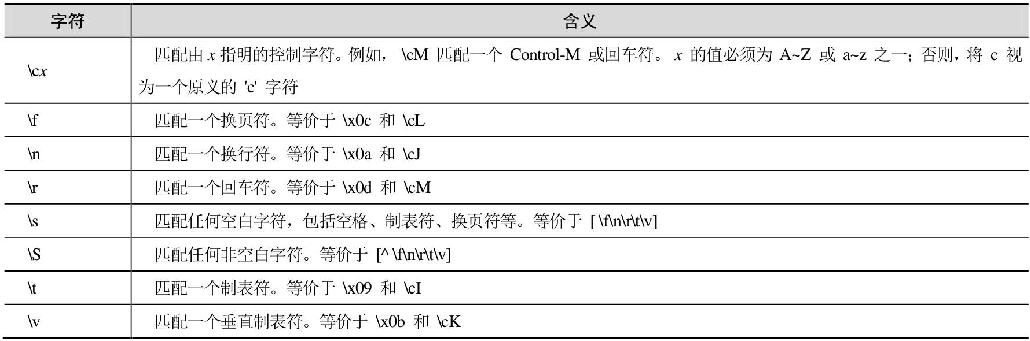
有不少很有用的非打印字符,偶尔必须使用。表16.2显示了用来表示这些非打印字符的转义序列。
表16.2 非打印字符表
16.2.4 限定符及贪婪模式和非贪婪模式
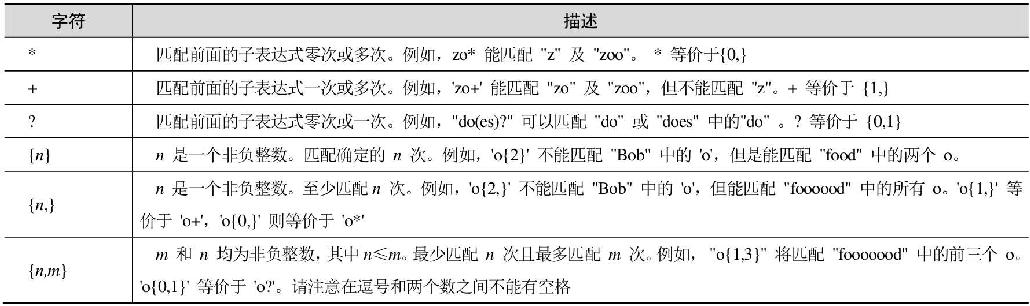
有时候不知道要匹配多少字符。为了能适应这种不确定性,正则表达式支持限定符的概念。这些限定符可以指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。表16.3给出了各种限定符及其含义的说明。
表16.3 限定符表
对一个很大的输入文档,章节数很轻易就超过9,因此需要有一种方法来处理两位数或者三位数的章节号。限定符就提供了这个功能。下面的PHP正则表达式可以匹配具有任何位数的章节标题:
/Chapter [1-9][0-9]*/
请注意限定符出现在范围表达式之后。因此,它将应用于所包含的整个范围表达式,在本例中,只指定了从0到9的数字。
这里没有使用“+”限定符,因为第二位或后续位置上并不一定需要一个数字。同样也没有使用“?”字符,因为这将把章节数限制为只有两位数字。在“Chapter”和空格字符之后至少要匹配一个数字。
如果已知章节数限制为99章,则可以使用下面的正则表达式来指定至少有一位数字,但不超过两个数字。
/Chapter [1-9][0-9]?/
以上是使用限定符的正则匹配示例,它们都是贪婪的。那如何是贪婪的,又如何是非贪婪的呢?下面介绍贪婪模式和非贪婪模式的概念。
贪婪模式
“*”、“+”和“?”限定符都称为贪婪的,也就是说,它们尽可能多地匹配文字。所以本节所举的两个例子的正则就是贪婪模式的。
但是有时这不是所希望发生的情况。有时正好希望最小匹配,即非贪婪模式。
非贪婪模式
通过在“*”、“+”和“?”限定符后放置“?”,该表达式就从贪婪匹配转为了非贪婪或最小匹配。
下面举个例子说明一下。考虑这个表达式,如下:
/a.*b/
它将会匹配最长的以a开始、以b结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪匹配。
有时,更需要非贪婪匹配,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为非贪婪匹配模式,只要在它后面加上一个问号?。这样.*?就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。现在看看非贪婪版的例子:
/a.*?b/
匹配最短的,以a开始、以b结束的字符串。如果把它应用于aabab的话,它会匹配aab(第一到第三个字符)和ab(第四到第五个字符)。
16.2.5 定位符
用来描述字符串或单词的边界,“^”和“$”分别指字符串的开始与结束,“\b”描述单词的前或后边界,“\B”表示非单词边界。
不能对定位符使用限定符。因为在一个换行符或者单词边界的前面或后面不会有连续多个位置,因此诸如“^*”的表达式是不允许的。
要匹配一行文字开始位置的文字,请在正则表达式的开始处使用“^”字符。不要把“^”的这个语法与其在括号表达式中的语法弄混。
要匹配一行文字结束位置的文字,请在正则表达式的结束处使用“$”字符。
要在查找章节标题时使用定位符,下面的正则表达式将匹配位于一行的开始处最多有两个数字的章节标题:
/^Chapter [1-9][0-9]{0,1}/
一个真正的章节标题不仅出现在一行的开始,而且这一行中也仅有这一个内容,因此,它必然也位于一行的结束。下面的表达式确保所指定的匹配只匹配章节而不会匹配交叉引用。它是通过创建一个只匹配一行文字的开始和结束位置的正则表达式来实现的。
/^Chapter [1-9][0-9]{0,1}$/
16.2.6 选择与编组
用圆括号将所有选择项括起来,相邻的选择项之间用“|”分隔。但用圆括号会有一个副作用,即相关的匹配会被缓存,此时可用“?:”放在第一个选项前来消除这种副作用。
其中“?:”是非捕获元之一,还有两个非捕获元是“?=”和“?!”。这两个还有更多的含义:前者为正向预查,在任何开始匹配圆括号内的正则表达式模式的位置来匹配搜索字符串;后者为负向预查,在任何开始不匹配该正则表达式模式的位置来匹配搜索字符串。
假定有一个包含引用了Windows 2000、Windows XP、Windows Vista及Windows 7的文档。进一步假设需要更新该文档,方法是查找所有对 Windows 2000、Windows XP 及Windows 7的引用,这时可以使用下面的正则表达式,这是一个正向预查,如下所示:
/Windows(?=2000|XP|7)/
16.2.7 后向引用
对一个正则表达式模式或部分模式两边添加圆括号将导致相关匹配存储到一个临时缓冲区中,所捕获的每个子匹配都按照在正则表达式模式中从左至右所遇到的内容存储。存储子匹配的缓冲区编号从1开始,连续编号直至最大99个子表达式。每个缓冲区都可以使用“\n”访问,其中n为一个标识特定缓冲区的一位或两位十进制数。
Tips 可以使用非捕获元字符“?:”、“?=”或者“?!”来忽略对相关匹配的保存。
所捕获的每个子匹配都按照在正则表达式模式中从左至右所遇到的内容存储。存储子匹配的缓冲区编号从1开始,连续编号直至最大99个子表达式。每个缓冲区都可以使用“\n”访问,其中n为一个标识特定缓冲区的一位或两位十进制数。
后向引用一个最简单、最有用的应用是提供了确定文字中连续出现两个相同单词的位置的能力。请看下面的句子:
Is is the cost of of gasoline going up up?
根据所写内容,上面的句子明显存在单词多次重复的问题。如果能有一种方法无须查找每个单词的重复现象就能修改该句子就好了。下面的正则表达式使用一个子表达式就可以实现这一功能:
/\b([a-z]+) \1\b/gi
在这个示例中,子表达式就是圆括号之间的每一项。所捕获的表达式包括一个或多个字母字符,即由“[a-z]+”所指定的。该正则表达式的第二部分是对前面所捕获的子匹配的引用,也就是由附加表达式所匹配的第二次出现的单词。“\1”用来指定第一个子匹配。单词边界元字符确保只检测单独的单词。如果不这样,则诸如“is issued”或“this is”这样的短语都会被该表达式不正确地识别。
16.2.8 各操作符的优先级
在构造正则表达式之后,就可以像数学表达式一样来求值,也就是说,可以从左至右并按照一个优先权顺序来求值。表16.4从最高优先级到最低优先级列出了各种正则表达式操作符的优先权顺序。
表16.4 优先级表

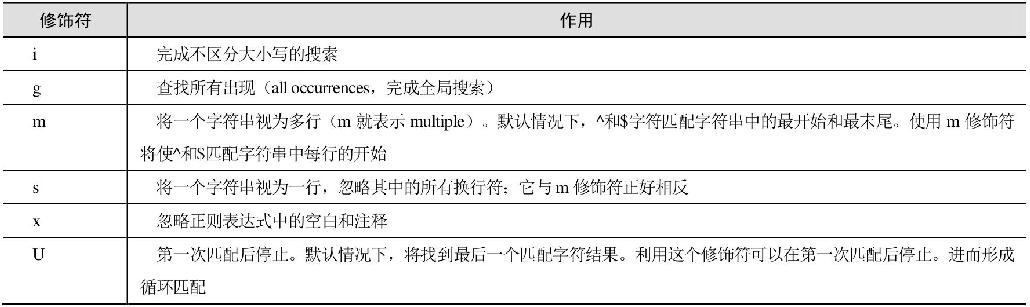
16.2.9 修饰符
在正则表达式中的修饰符,是用来进一步描述正则所匹配的内容的。它需要被放在定界符的后面,如匹配一个不区分大小写的“cat”的正则,可以这样写:
/cat/i
其中的“i”就是修饰符,这里表示不区分大小写的意思。表16.5列出的是PHP正则中允许的修饰符。
表16.5 修饰符表
16.3 PHP中相关正则表达式的函数
在有了正则表达式之后,下面介绍在PHP中如何使用相关正则表达式的函数,对相应的字符串进行操作。
16.3.1 用正则表达式检查字符串是否为规定格式
在PHP中提供正则函数preg_match()来验证匹配,语法如下:
int preg_match ( string pattern, string subject [, array matches [, int flags]] )
该函数在subject字符串中搜索与pattern给出的正则表达式相匹配的内容。如果提供了matches,则其会被搜索的结果所填充。$matches[0]将包含与整个模式匹配的文本,$matches[1]将包含与第一个捕获的括号中的子模式所匹配的文本,以此类推。
preg_match()返回pattern所匹配的次数。是0次(没有匹配)或1次,因为preg_match()在第一次匹配之后将停止搜索。
注意 PHP同样提供ereg()函数来验证正则对字符串的匹配,但是并不推荐使用。
Tips 如果只想查看一个字符串是否包含在另一个字符串中,虽然可以使用preg_match()来判断,但是建议用strpos()或strstr()替代,后者判断速度要快得多。
首先从简单的开始。假设要搜索一个包含字符“cat”的字符串,搜索用的正则表达式就是“cat”。如果搜索对大小写不敏感,单词“catalog”、“Catherine”、“sophisticated”都可以匹配。下面是实现这个功能的一个例子,如代码16-1所示。
代码16-1 一个简单的正则表达式
<span class="kindle-cn-bold">一个简单的正则表达式</span><hr /><p>
正则表达式:/cat/i
<?php
// 模式定界符后面的“i”表示不区分大小写字母的搜索
if (preg_match ("/cat/i", "catalog")) { //使用preg_match与catalog进行匹配
echo "<p>catalog is matched.";
} else {
echo "<p>catalog is not matched.";
}
if (preg_match ("/cat/i", "Catherine")) { //使用preg_match与Catherine进行匹配
echo "<p>Catherine is matched.";
} else {
echo "<p>Catherine is not found.";
}
if (preg_match ("/cat/i", "sophisticated")) { //使用preg_match与sophisticated进行匹配
echo "<p>sophisticated is matched.";
} else {
echo "<p>sophisticated is not matched.";
}
if (preg_match ("/cat/i", "emmma")) { //使用preg_match与emmma进行匹配
echo "<p>emmma is matched.";
} else {
echo "<p>emmma is not matched.";
}
?>
以上代码使用同一个正则表达式分别与4个不同的字符串进行匹配,根据匹配结果的不同返回不同的信息。页面执行后,得到的结果如图16.1所示。
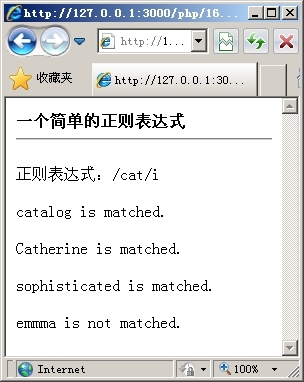
图16.1 一个简单的正则表达式
Tips 在本例中使用的定界符是反斜杠,也可以是其他字符,比如#、$等。
16.3.2 将字符串中特定的部分替换掉
查找字符串中某个特定的部分并替换成指定的字符,这也是一个经常遇到的问题。PHP提供preg_replace()函数来实现这个功能,其使用语法如下所示:
mixed preg_replace ( mixed pattern, mixed replacement, mixed subject [, int limit] )
该函数在subject中搜索pattern模式的匹配项并替换为replacement。如果指定了limit,则仅替换limit个匹配;如果省略limit或者其值为-1,则所有的匹配项都会被替换。
replacement可以包含\\n形式或(自PHP 4.0.4起)$n形式的逆向引用,首选使用后者。每个此种引用将被替换为与第n个被捕获的括号内的子模式所匹配的文本。n可以从0到99,其中\\0或$0指的是被整个模式所匹配的文本。对左圆括号从左到右计数(从1开始)以取得子模式的数目。
对替换模式在一个逆向引用后面紧接着一个数字时(即:紧接在一个匹配的模式后面的数字),不能使用熟悉的\\1符号来表示逆向引用。比如\\11,它将会使preg_replace()搞不清楚是想要一个\\1的逆向引用后面跟着一个数字1还是一个\\11的逆向引用。这个问题的解决方法是使用\${1}1。这会形成一个隔离的$1逆向引用,而使另一个1只是单纯的文字。
代码16-2是将字符串中所有“菠菜”替换成“白菜”的一个例子,如下所示。
代码16-2 将字符串中特定的部分替换掉
<span class="kindle-cn-bold">将字符串中特定的部分替换掉</span><hr /><p> <?php $string = "菠菜原产于我国北方,俗称大菠菜"; //原字符串 echo "<p>原字符串:" . $string; //输出原字符串 $pattern = "/菠菜/"; //查找的文字 $replacement = "白菜"; //替换后的文字 echo "<p>替换后的字符串:" ; echo preg_replace($pattern, $replacement, $string); //输出替换后的文字 ?>
以上代码使用preg_replace()函数将“菠菜”替换成“白菜”,然后直接返回被替换后的字符串。运行后得到的结果如图16.2所示。
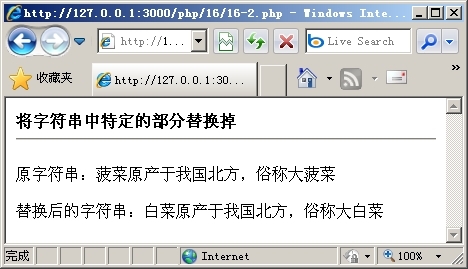
图16.2 将字符串中特定的部分替换掉
16.3.3 取得字符串中符合规定的部分
取得字符串中符合规定的部分也是一个常用的功能,本节通过一个提交网页中所有链接的例子来说明如何使用。需要用到PHP提供的preg_match_all()函数,其使用语法如下所示:
int preg_match_all ( string pattern, string subject, array matches [, int flags] )
该函数在subject中搜索所有与pattern给出的正则表达式匹配的内容并将结果以flags指定的顺序放到matches中。搜索到第一个匹配项之后,接下来的搜索从上一个匹配项末尾开始。matches会被搜索的结果所填充,$matches[0]将包含与整个模式匹配的文本,$matches[1]将包含与第一个捕获的括号中的子模式所匹配的文本,以此类推。
注意 也可以使用前面提到的preg_match()函数取得字符串中符合规定的部分,但是它只能得到第一次的匹配。
下面实现一个取得页面中所有链接地址的例子,如代码16-3所示。
代码16-3 取得页面中所有的链接地址
<span class="kindle-cn-bold">取得页面中所有的链接地址</span><hr /><p>
<?php
$html = file_get_contents("http://www.mahuu.com"); //取得页面的源代码
$html = mb_convert_encoding($html, "GBK", "UTF-8"); //进行转码操作
$a = "/<a[\s]+[^>]*href\=[\"']?([^>'\"]+)[\"']?[^>]*>/i"; //匹配链接地址的正则
preg_match_all($a, $html, $matches); //取得所有的匹配放入$matches
for ($i=0; $i< count($matches[0]); $i++) { //循环所有的匹配
echo "<p>" . $matches[1][$i]; //输出链接地址
}
?>
在以上代码中,使用file_get_contents()函数来取得一个网络上已有的页面。因为这个页面是“UTF-8”编码的,直接显示出来可能会出现乱码的情况,所以要再使用mb_convert_encoding()将它转成“GBK”码。之后需要重点注意的是匹配链接地址的正则“/<a[\s]+[^>]*href\= [\"']? ([^>'\"]+)[\"']?[^>]*>/i”,解释如下:
/<a[\s]+[^>]*href=[\"']?([^>'\"]+)[\"']?[^>]*>/i
|-------|(1)
|----| |-----|(2)
|-----------------------------|(3)
|----------|(4)
(1)所指示的正则表示匹配“<a”与其后的一个以上空格;(2)表示匹配所有不包含“>”符号的字符;(3)表示匹配“href=”与其所跟的链接地址;(4)表示匹配的超级链接。运行后得到的结果如图16.3所示。
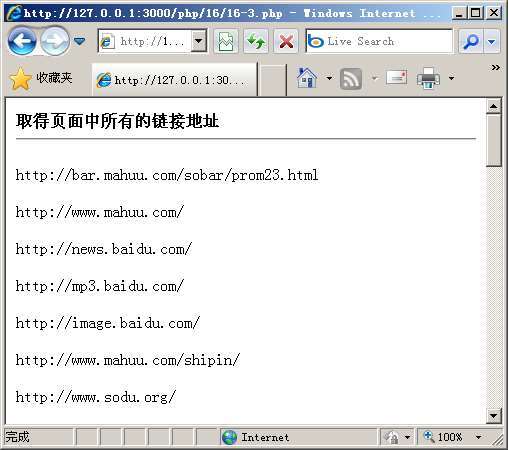
图16.3 取得页面中所有的链接地址
16.4 典型实例
有了以上的正则基础以后,本节就来介绍几个常用的正则表达式。本节所介绍的正则表达式都是在注册用户时所需要用到的一些注册信息的验证。
【实例16-1】检测邮件地址的有效性。
现在的网站注册用户时一般都需要填写电子邮件地址,本节实例给出一种校验邮件地址有效性的实现方法,如代码16-4所示。
代码16-4 检测邮件地址的有效性
<span class="kindle-cn-bold">邮件地址的有效性</span><hr><p>
<?php
if($_GET['act'] == "validate") { //如果act为validate则开始验证
/*使用preg_match函数配合电子邮件的正则进行验证*/
if
(preg_match("/^[a-z0-9]+([_\.-]*[a-z0-9]+)*@[a-z0-9]([-]?[a-z0-9]+)\.[a-z]{2,3}(\.[a-z]{2})?$/i",
$_POST['email'])) {
echo "<font color='green'>此email有效!</font>"; //有效时的输出
} else {
echo "<font color='red'>此email无效!</font>"; //无效时的输出
}
die(); //停止解析
}
?>
<form action="?act=validate" method="post">
<input name="email" type="text">
<br /><br />
<input type="submit" value="验证">
</form>
以上代码首次运行时会显示一个提交表单,在输入框中输入需要验证的电子邮件地址,如图16.4所示。单击“验证”按钮以后,便会出现验证后的结果,如图16.5所示。
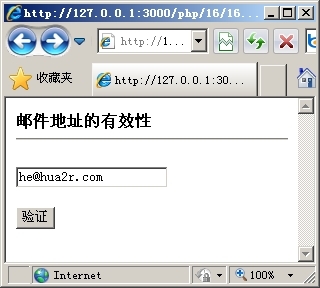 |
 |
| 图16.4 输入电子邮件地址 | 图16.5 验证地址有效 |
这里对例子中使用的电子邮件验证的正则做一下解释,如下所示:
^[a-z0-9]+([_\.-]*[a-z0-9]+)*@[a-z0-9]([-]?[a-z0-9]+)\.[a-z]{2,3}(\.[a-z]{2})?$
|----------------------------------|(1)
|----------------------------|(2)
|-----------|(3)
|-------|(4)
(1)所指示的正则表示匹配“@”符号前的用户名;(2)表示“@”符号后第一个“。”符号前的域名;(3)表示匹配第一个“。”符号后的域名后缀;(4)匹配域名的第二个后缀。
【实例16-2】检查电话号码的有效性。
本节实例给出一种校验电话号码有效性的实现方法,如代码16-5所示。
代码16-5 检查电话号码的有效性
<span class="kindle-cn-bold">验证电话号码的有效性</span><hr><p>
<?php
if($_GET['act'] == "validate") { //如果act为validate则开始验证
/*使用preg_match函数配合电话号码的正则进行验证*/
if (preg_match("/^[+]?[0-9]+([xX-][0-9]+)*$/i", $_POST['tel'])) {
echo "<font color='green'>此电话号码有效!</font>"; //有效时的输出
} else {
echo "<font color='red'>此电话号码无效!</font>"; //无效时的输出
}
die(); //停止解析
}
?>
<form action="?act=validate" method="post">
<input name="tel" type="text">
<br /><br />
<input type="submit" value="验证">
</form>
首先对代码中的正则做一下解释,“[+]?[0-9]+”表示电话号码的区号,“[xX-]”表示区号与号码之间允许的分隔符,“[0-9]+”匹配的就是电话号码。
以上代码首次运行时会显示一个提交表单,在输入框中输入需要验证的电话号码,如图16.6所示。单击“验证”按钮以后,便会出现验证后的结果,如图16.7所示。
 |
 |
| 图16.6 输入电话号码 | 图16.7 验证电话号码有效 |
【实例16-3】用户名的有效性检测。
本节实例给出一种校验用户名的实现方法,如代码16-6所示。
代码16-6 用户名的有效性检测
<span class="kindle-cn-bold">验证用户名的有效性</span><hr><p>
<?php
if($_GET['act'] == "validate") { //如果act为validate则开始验证
/*使用preg_match函数配合用户名的正则进行验证*/
if (preg_match("/^[_a-zA-Z0-9]*$/i", $_POST['name'])) {
echo "<font color='green'>此用户名有效!</font>"; //有效时的输出
} else {
echo "<font color='red'>此用户名无效!</font>"; //无效时的输出
}
die(); //停止解析
}
?>
<form action="?act=validate" method="post">
<input name="name" type="text">
<br /><br />
<input type="submit" value="验证">
</form>
同样先对使用的正则表达式解释一下,“[_a-zA-Z0-9]*”表示含有字母、下画线和数字的任意个组合。
以上代码首次运行时会显示一个提交表单,在输入框中输入需要验证的用户名,如图16.8所示。单击“验证”按钮以后,便会出现验证后的结果,如图16.9所示。
 |
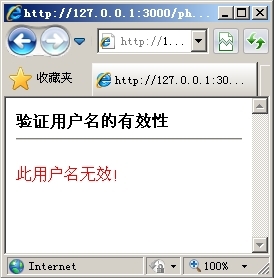 |
| 图16.8 输入用户名 | 图16.9 验证用户名无效 |
【实例16-4】中文字符的有效性检测。
本节实例给出一种校验中文字符有效性的实现方法,如代码16-7所示。
代码16-7 中文字符的有效性检测
<span class="kindle-cn-bold">验证中文字符的有效性</span><hr><p>
<?php
if($_GET['act'] == "validate") { //如果act为validate则开始验证
/*使用preg_match函数配合用户名的正则进行验证*/
//"/^[\x{4e00}-\x{9fa5}]+$/" //当编码为utf-8时的正则
if (preg_match("/^[".chr(0xa1)."-".chr(0xff)."]+$/", $_POST['name'])) {
echo "<font color='green'>此中文字符有效!</font>"; //有效时的输出
} else {
echo "<font color='red'>此中文字符无效!</font>"; //无效时的输出
}
die(); //停止解析
}
?>
<form action="?act=validate" method="post">
<input name="name" type="text">
<br /><br />
<input type="submit" value="验证">
</form>
其中的正则表达式的“chr(0xa1)”是汉字的起始内码,“chr(0xff)”是汉字的终止内码。这样就能容易地理解这个表达式匹配的是中文字符了。不过这个只能应用在“GB2312”编码的字符串上。如果是“UTF-8”编码的字符串就需要用正则表达式“/^[\x{4e00}-\x{9fa5}]+$/”。
以上代码首次运行时会显示一个提交表单,在输入框中输入需要验证的中文字符,如图16.10所示。单击“验证”按钮以后,便会出现验证后的结果,如图16.11所示。
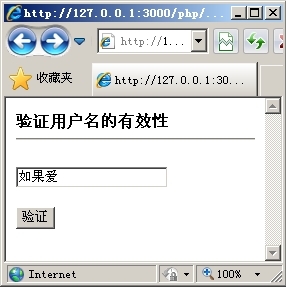 |
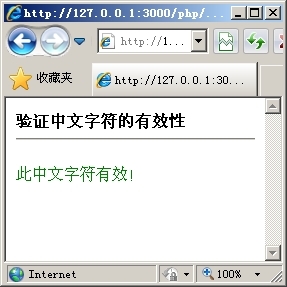 |
| 图16.10 输入中文字符 | 图16.11 验证中文字符有效 |
16.5 小结
本章主要讲述了正则表达式匹配规则和一些元字符的应用,以及在PHP中处理它们的函数。正则表达式对检验数据是否合法是非常有用的,其实现过程也十分简单有效,掌握正则表达式对简化查找、替换、判断等过程都很有帮助。
16.6 习题
一、填空题
1. 进行全局正则表达式匹配的函数是__________。
2. PHP还提供了代表字符类的元符号:符号_____、_____分别代表单个数字和单个非数字,相当于[0-9]和[^0-9]。
3. 元字符+用来匹配前面的子表达式__________。
4. 正则表达式/^abc/的意义是__________。
5. 利用正则表达式分隔字符串的函数是__________。
6. 函数preg replace callback()和preg replace()作用一样,除了不是提供一个replacement参数,而是指定一个__________。
7. 字符簇[0-9\.\-]表示的意义是__________。
8. 字符簇[^a-z]表示的意义是__________。
二、选择题
1. 元字符$代表的意义是( )。
A. 匹配字符串开始位置
B. 匹配字符串的结尾位置
C. 匹配字符串开始和结束位置
D. 匹配字符串任何位置
2. 元字符a{3,}表示的意义是( )。
A. 匹配a、{、,
B. 匹配重复3次的字母a
C. 匹配少于重复3次的字母a
D. 匹配重复3次以上的字母a
3. 正则表达式/href=’(.*)’表示( )。
A. 合法
B. 含有未知修正符
C. 缺少起始定界符
D. 缺少结束定界符
4. 正则表达式/abc$/表示( )。
A. 匹配字符串abc$
B. 匹配以abc开头的字符串
C. 匹配以abc结尾的字符串
D. 匹配任意的abc字符串
5. 下列程序的运行结果为( )。
$result=preg match(“/word/”,”This string have ten words”);
if ($result){
echo “匹配成功<br>”;
}
else
echo “匹配不成功”
A. 无任何输出
B. 输出“匹配成功”
C. 输出“匹配不成功”
D. 程序有误
三、简答题
1. 简要说明什么是字符簇,它们的作用是什么。
2. 阐述preg match all()函数中各参数的意义。
四、编程题
1. 利用正则表达式判断邮件地址是否有效。
2. 利用正则表达式匹配"<H3>留言板</H3><div align=left>请您留言:</div>",此内容按格式输出到浏览器上,再将题目改为“历史回顾”。