第15章 PHP与XML
XML(eXtensible Markup Language,可扩展标记语言)技术作为一种工具正广泛应用于程序与程序之间的数据传递,因为不同种类的数据都能使用XML作为中间数据,实现数据的无缝兼容。当然PHP也支持XML的操作,本章就向读者介绍如何使用PHP对XML文件进行各种操作。
15.1 XML快速入门
在深入学习XML以前,先来了解一下什么是XML。然后再通过建立一个简单的XML,开始循序渐进的学习。
15.1.1 什么是XML
XML即可扩展标记语言(Extensible Markup Language),是一种与平台无关的表示数据的方法。简单地说,使用XML创建的数据可以被任何应用程序在任何平台上读取。甚至可以通过手动编码来编辑和创建XML文档。其原因是,XML与HTML一样,都是建立在相同的基于标记技术基础之上。
15.1.2 XML、HTML和SGML之间的关系和区别
XML和HTML都来自于SGML,它们都含有标记,有着相似的语法;HTML和XML的最大区别在于:HTML是一个定型的标记语言,它用固有的标记来描述,显示网页内容。比如<H1>表示首行标题,有固定的尺寸。相对的,XML则没有固定的标记,XML不能描述网页具体的外观、内容,它只是描述内容的数据形式和结构。
这是一个质的区别:网页将数据和显示混在一起,而XML则将数据和显示分开来。
正是这种区别使得XML在网络应用和信息共享上更方便、高效、可扩展。所以我们相信,XML作为一种先进的数据处理方法,将使网络进入到一个新的境界。
15.1.3 建立一个简单的XML文件
接下来就来建立一个简单的XML文件,这个文件包含了一条小奀发给小林的一条信息,如代码15-1所示。
代码15-1 一个简单的XML文件
<?xml version="1.0" encoding="gb2312" ?>
<note>
<from>小奀</from>
<to>小林</to>
<message>周末一起去吃火锅呀</message>
</note>
文档的第1行是XML声明,定义此文档所遵循的XML标准的版本,在这个例子里是1.0版本的标准,使用的是“GB2312”字符集。
文档的第2行是根元素(就像是说“这篇文档是一个便条”):
<note>
文档的第3~6行描述了根元素的3个子节点(from,to和message):
<from>小奀</from> <to>小林</to> <message>周末一起去吃火锅呀</message>
文档的最后一行是根元素的结束:
</note>
使用浏览器浏览这个文档看到的效果如图15.1所示。
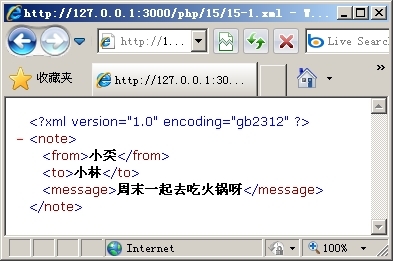
图15.1 一个简单的XML文件
15.2 深入XML文档
15.1节介绍了什么是XML,以及相关的信息,并建立一个简单的XML文档,本节就在这一基础上深入地讨论XML文档的规定。
15.2.1 XML声明
如果可以知道某个XML文档属于哪个类型,这对于我们非常有用。在Windows平台上,文件扩展名.xml表示它是一个XML文档,但是对于其他操作系统平台,这种方法不起作用。此外,用户也可能希望用其他扩展名创建XML文件。
XML提供了XML声明语句,说明文档是属于XML类型。此外这个声明语句还给解析器提供其他信息。也可以不使用XML声明,因为没有这个声明语句,解析器通常也能够判断一个文档是否是XML文档,但是加上XML声明语句被认为是一个很好的习惯。下面是几点有关XML声明语句的说明。
- XML声明语句从<?xml开始,到?>结束。
- 声明语句里必须有version(版本)属性,但是encoding(编码)和standalone(独立)属性是可选的。
- version、encoding和standalone 3个属性必须按上述(第二点)顺序排列。
- version属性值必须是1.0或1.1,表示版本信息。
- XML声明必须放在文件的开头,即文件的第一个字符必须是<,前面不能有空行或空格,关于这一点,有些解析器不那么严格。
例如,XML声明语句可以像前面那样复杂,也可以像下面这样简单:
<?xml version=”1.0”?>
15.2.2 元素的概念
XML元素是指从该元素的开始标记到结束标记之间的这部分内容。XML元素有元素内容、混合内容、简单内容或者空内容,且每个元素都可以拥有自己的属性。看如下的一段XML代码:
<book> <title>XML 指南</title> <prod id="33-657" media="paper"></prod><chapter>XML入门简介 <para>什么是HTML</para> <para>什么是XML</para> </chapter> <chapter>XML语法 <para>XML元素必须有结束标记</para> <para>XML元素必须正确的嵌套</para> </chapter> </book>
在上面的例子中,book元素有元素内容,因为book元素包含了其他的元素。Chapter元素有混合内容,因为它里面包含了文本和其他元素。para元素有简单的内容,因为它里面仅有简单的文本。prod元素有空内容,因为它不携带任何信息。
在上面的例子中,只有prod元素有属性,id属性值是33-657,media属性值是paper。
其中XML元素命名必须遵守下面的规则。
- 元素的名字可以包含字母、数字和其他字符。
- 元素的名字不能以数字或者标点符号开头。
- 元素的名字不能以XML(或者xml,Xml,xMl...)开头。
- 元素的名字不能包含空格。
自己“发明”的XML元素还必须注意下面一些简单的规则。
任何的名字都可以使用,没有保留字(除了XML),但是应该使元素的名字具有可读性;名字使用下画线是一个不错的选择。尽量避免使用“-”、“.”,因为有可能引起混乱。
XML文档往往都对应着数据表,应该尽量让数据库中的字段的命名和相应的XML文档中的命名保持一致,这样可以方便数据变换。
非英文的字符和字符串也可以作为XML元素的名字,例如<我爱中国><诸子百家>这都是完全合法的名字;但是有一些软件不能很好地支持这种命名,所以尽量使用英文字母来命名。
在XML元素命名中不要使用“:”,因为XML命名空间需要用到这个十分特殊的字符。
15.2.3 标记和属性
置标能够区分XML文件与无格式文本文件。置标的最大部分是标记。简而言之,标记在XML文档中以<开始,以>结束,而且不包含在注释或者CDATA段中。因此,XML标记有与HTML标记相同的形式。开始或打开标记以<开始,后面跟有标记名;终止或结束标记以</开始,后面也跟标记名。遇到的第一个>该标记结束。
属性是不能包含其他元素的命名的简单类型定义。属性也可以被分配一个可选默认值,且必须出现在复杂类型定义的底部。此外,如果声明了多个属性,它们可以以任意顺序出现。
15.2.4 Well-formed XML(结构良好的XML)
符合全部XML语法规则的XML文档是结构良好的。结构不良好的文档从技术上讲就不是XML。<br>之类的HTML标记在XML中是不允许的,要想成为结构良好的XML,必须写成<br />。解析器不能正确解析结构不良好的XML。此外,XML文档有且只能有一个根元素。可以将根元素看成是有无穷层的文件柜。虽然只有一个文件柜,但是在其中放什么和放多少没有什么限制。有数不清的抽屉和夹子可以存放信息。
注意 使用一些工具,比如“XMLSpy 2006”就可以测试某文档是否为结构良好的XML文档。
15.2.5 Valid XML(有效的XML)
有效的XML文档是指通过了DTD验证的XML文档。在此大家要明白XML文档可分为结构良好的XML文档和有效的XML文档,以及它们之间的关系;即具有良好结构的XML文档并不一定就是有效的XML文档,反之一个有效的XML文档必定是一个结构良好的XML文档。
15.2.6 DTD(文件类型定义)
DTD是一种保证XML文档格式正确的有效方法,可以通过比较XML文档和DTD文件来查看文档是否符合规范,元素和标签使用是否正确。一个DTD文档包含:元素的定义规则,元素间关系的定义规则,元素可使用的属性,可使用的实体或符号规则。
每一个XML文档都可携带一个DTD,用来对该文档格式进行描述,测试该文档是否为有效的XML文档。既然DTD有外部和内部之分,当然就可以为某个独立的团体定义一个公用的外部DTD;那么多个XML文档就都可以共享使用该DTD,使得数据交换更为有效。甚至在某些文档中还可以使内部DTD和外部DTD相结合。在应用程序中也可以用某个DTD来检测接收到的数据是否符合某个标准。
对于XML文档而言,虽然DTD不是必需的,但它为文档的编制带来了方便;加强了文档标记内参数的一致性,使XML语法分析器能够确认文档。如果不使用DTD对XML文档进行定义,那么XML语法分析器将无法对该文档进行确认。
15.3 用SimpleXML处理XML文档
讲了那么多XML的知识,想必大家最关心的还是如何使用PHP来处理它,本节就来讲解如何使用PHP的SimpleXML来处理XML文档。SimpleXML提供了一种简单直观的方法来处理XML。它只有一个单一类型的类、3个函数和6个方法。
15.3.1 建立一个SimpleXML对象
使用SimpleXML处理XML文档,首先要做的就是建立SimpleXML对象。SimpleXMLElement类是这个扩展中所有操作的核心类。可以用new关键字直接创建这种类,或者使用simplexml_load_file()或simplexml_load_string()函数返回这种类。
使用new方式创建SimpleXML对象的方法如下:
$xml = "<root><node1>Content</node1></root>"; //一个字符形式的XML文档 $sxe = new SimpleXMLElement($xml); //使用new方法创建SimpleXML对象
使用simplexml_load_string()创建:
$xml = "<root><node1>Content</node1></root>"; //一个字符形式的XML文档 $sxe = simplexml_load_string($xml); //使用simplexml_load_string方法创建SimpleXML对象
如何选择这两种创建SimpleXMLElement的方法呢?simplexml_load_string()提供了更多的参数选择,比如控制解析选项的能力。如果不需要这些额外的函数,那么就可以凭个人爱好任意选择一种方法。
使用simplexml_load_file()从一个URI创建:
$sxe = simplexml_load_file("filename.xml");
使用该方法能在已有的文件上直接创建SimpleXML对象。
15.3.2 XML数据的读取
与操作数组类型的变量类似,读取XML也可以通过类似的方法来完成。首先需要一个XML数据源,如代码15-2所示。
代码15-2 一个XML文档
<?xml version="1.0" encoding="gb2312" ?>
<book>
<title>XML 指南</title>
<prod id="33-657" media="paper"></prod>
<chapter>XML入门简介
<para>什么是HTML</para>
<para>什么是XML</para>
</chapter>
<chapter>XML语法
<para>XML元素必须有结束标记</para>
<para>XML元素必须正确地嵌套</para>
</chapter>
</book>
如果需要读取上面XML数据中每一个“chapter”标签下的“para”属性,可以通过使用foreach函数来完成,如以下代码所示。
<?php
$xml = simplexml_load_file('15-2.xml'); //载入XML文档
foreach($xml->chapter as $a) { //循环读取
echo $a->para . '<br />'; //输出para元素的内容
}
?>
运行后得到的结果如下:
什么是HTML XML元素必须有结束标记
也可以使用方括号“[]”来直接读取XML数据中指定的标签。以下的代码输出了上面XML数据中的第一个“chapter”标签下的“para”属性。
<?php
$xml = simplexml_load_file('15-2.xml'); //载入XML文档
echo $xml->chapter->para[0] . '<br />'; //读取根节点下的chapter节点下的第一个para
echo $xml->chapter->para[1] . '<br />'; //读取根节点下的chapter节点下的第二个para
?>
运行后得到的结果如下:
什么是HTML 什么是XML
对于一个标签下的所有子标签,SimpleXML组件提供了children方法进行读取。例如,对于上面的XML数据中的“chapter”标签下的子标签的读取。
<pre>
<?php
$xml = simplexml_load_file('15-2.xml'); //载入XML文档
foreach($xml->chapter->children() as $a) { //循环子节点
var_dump($a); //输出源结构
}
?>
≶/pre>
运行得到的结果如下:
object(SimpleXMLElement)#3 (1) {
[0]=>
string(13) "什么是HTML"
}
object(SimpleXMLElement)#5 (1) {
[0]=>
string(12) "什么是XML"
}
可以看出,使用children方法后,所有的子标签均被当作一个新的XML文件进行处理。
以上方法是读取XML标签元素的内容,下面介绍如何读取元素中的属性。此时需要用到attributes方法。例如,以下代码完成了对于上面的XML数据中的“prod”标签下的“media”属性的读取。
<?php
$xml = simplexml_load_file('15-2.xml'); //载入XML文档
echo $xml->prod->attributes()->media; //使用attributes方式读取属性
echo '<br />';
echo $xml->prod['media']; //另外一种读取属性的方式
?>
运行后得到的结果如下:
paper paper
SimpleXML组件提供了一种基于XML数据路径的查询方法。XML数据路径即从XML的根到某一个标签所经过的全部标签。这种路径使用斜线“/”隔开标签名。例如,对于上面的XML数据,要查询所有的标签“para”中的值,从根开始要经过book、chapter和para标签,则其路径为“/book/chapter/para”。
SimpleXML组件使用xpath方法来解析路径,该方法接受一个XPath路径返回的包含有所有查询标签值的数组。以下代码查询了上面XML数据中的所有para标签。
<pre>
<?php
$xml = simplexml_load_file('15-2.xml'); //载入XML文挡
$result = $xml->xpath('/book/chapter/para'); //使用XPath查询
var_dump($result); //输出结果
?>
</pre>
运行后得到的结果如下所示。
array(4) {
[0]=>
object(SimpleXMLElement)#2 (1) {
[0]=>
string(13) "什么是HTML"
}
[1]=>
object(SimpleXMLElement)#3 (1) {
[0]=>
string(12) "什么是XML"
}
[2]=>
object(SimpleXMLElement)#4 (1) {
[0]=>
string(30) "XML元素必须有结束标记"
}
[3]=>
object(SimpleXMLElement)#5 (1) {
[0]=>
string(30) "XML元素必须正确地嵌套"
}
}
15.3.3 XML数据的修改
对于XML数据的修改与读取XML数据中的标签方法类似,即通过直接修改SimpleXML对象中的标签的值来实现。以下代码实现了对上面XML数据中第一个“chapter”标签的“para”标签的修改。
<?php
$xml = simplexml_load_file('15-2.xml'); //载入XML文挡
$xml->chapter->para[0] = "实事求是"; //修改内容
?>
经历这个过程后,并不会对原有的XML文件有任何影响。但是,在程序中,对于SimpleXML对象的读取将使用修改过的值。
15.3.4 XML数据的保存
将SimpleXML对象中的XML数据存储到一个XML文件中的方法非常简单,即将asXML方法的返回结果输出到一个文件中即可。以下代码首先将XML文件中的chapter节点下的para进行了修改,然后将修改过的XML数据输出到另一个XML文件中。
<?php
$xml = simplexml_load_file('15-2.xml'); //载入XML文档
$ch_str = mb_convert_encoding("实事求是", "UTF-8", "GBK"); //将要修改成的中文转成UTF-8编码格式
$xml->chapter->para[0] = $ch_str; //修改内容
$new_xml = $xml->asXML(); //得到xml文档
file_put_contents("new.xml", $new_xml); //保存成文件
?>
对于以上代码需要注意的是,SimpleXML对象对中文等语言的修改操作都是基于“UTF-8”格式的,所以在本例中首先是将要修改的中文语言转成“UTF-8”格式,否则运行的时候会报错。
运行此代码前的XML文档如图15.2所示,运行后得到的新的XML文档如图15.3所示。
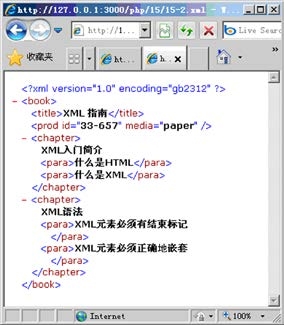 |
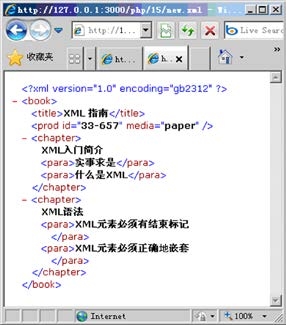 |
| 图15.2 修改前的原XML文档 | 图15.3 被修改后的XML文档 |
15.3.5 实例:从XML文件中读取新闻列表
在本节的最后,一起来实现一个读取新闻列表的例子。这里以百度的新闻RSS列表(http://news.baidu.com/n?cmd=1&class=civilnews&tn=rss)为范例,在浏览器中打开网页,如图15.4所示。
图15.4 百度新闻RSS
首先将这个RSS下载下来(便于查看原格式),保存成XML文件;使用文本编辑器查看结构,大概会是如图15.5所示的结构。
图15.5 RSS结构
有了RSS地址和结构以后就可以对其中的数据进行读取,下面的例子是对这个RSS的数据进行读取并显示,如代码15-3所示。
代码15-3 读取百度新闻RSS
<span class="kindle-cn-bold">读取百度新闻RSS</span><hr />
<?php
/*载入RSS地址,因为其中包含CDATA数据,所以将第三个参数设置为LIBXML_NOCDATA,可保证数据读取的正确性*/
$xml = simplexml_load_file('http://news.baidu.com/n?cmd=1&class=civilnews&tn=rss', 'SimpleXML
图Element', LIBXML_NOCDATA);
foreach($xml->channel->item as $item) { //循环读取RSS的内容
echo "标题:" . $item->title . "<br />"; //读取标题
echo "地址:" . $item->link . "<br />"; //读取链接
//读取时间并格式化
echo "时间:" . date('Y-m-d H:m:s', strtotime($item->pubDate)) . "<br />";
echo "出处:" . $item->author . "<br />"; //读取出处
//echo "摘要:" . $item->description . "<br />"; //读取描述
echo "<hr />";
}
?>
使用SimpleXML处理RSS新闻是非常方便的,首先通过simplexml_load_file载入RSS新闻列表,从代码中可以看到这里设置第三个参数为“LIBXML_NOCDATA”,是因为这个RSS中的内容是包含在CDATA标记中的,加上这个参数才能正确读取。此后就可以使用循环函数将需要读取的节点读出,图15.6就是运行以上代码后得到的结果。
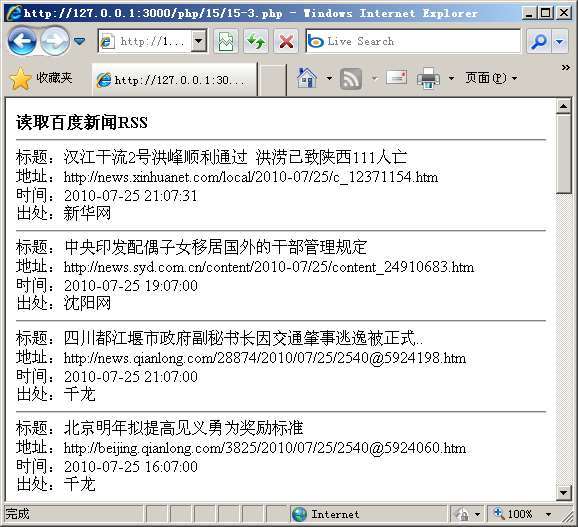
图15.6 读取RSS后的结果
15.4 使用DOM库处理XML文档
当然,PHP除了使用SimpleXML处理XML文档,还提供DOM库来实现同样的处理。与SimpleXML相比,它提供的功能要强大许多。
15.4.1 创建一个DOM对象并装载XML文档
要使用DOM库处理XML文档,首先要做的就是创建一个DOM对象,然后载入相应的XML文档。这两个步骤都是非常简单的。
创建DOM对象的语句如下所示:
$dom = new DOMDocument();
这样就创建了一个DOM对象。如果需要定义它的版本信息和编码方式,则语句如下:
$dom = new DOMDocument('1.0', 'iso-8859-1');
有了DOM对象之后就可以使用它的load()方法来载入一个已经存在的XML文档,示例如下:
$dom->load(simple.xml);
也可以直接载入XML片段:
$dom->loadXML('<root><node/></root>');
以下是载入并显示XML文档的一个例子,代码如下:
<?php
$doc = new DOMDocument(); //创建DOMDocument对象
$doc->load("15-2.xml"); //载入15-2.xml文档
echo $doc->saveXML(); //保存成一个字符串
?>
以上代码的输出:
XML入门简介 什么是HTML 什么是XML XML语法 XML元素必须有结束标记 XML元素必须正确地嵌套
假如在浏览器窗口中查看源代码,会看到下面这些HTML:
<?xml version="1.0" encoding="gb2312"?>
<book>
<title>XML 指南</title>
<prod id="33-657" media="paper"/>
<chapter>XML入门简介
<para>什么是HTML</para>
<para>什么是XML</para>
</chapter>
<chapter>XML语法
<para>XML元素必须有结束标记</para>
<para>XML元素必须正确地嵌套</para>
</chapter>
</book>
上面的例子创建了一个DOMDocument-Object,并把“15-2.xml”中的XML载入到这个文档对象中。saveXML()函数把内部XML文档放入一个字符串,这样就可以输出它。
15.4.2 获得特定元素的数组
如果读者了解JavaScript读取HTML某个指定标签的功能,肯定会联想到getElements ByTagName()函数。PHP的DOM库同样提供了这个函数来获得特定元素并把它们保存到一个数组中。下面的例子演示了如何从15.4.1节使用的XML中提取“para”元素,代码如下:
<pre>
<?php
$doc = new DOMDocument(); //创建DOMDocument对象
$doc->load("15-2.xml"); //载入15-2.xml文档
$nodes = $doc->getElementsByTagName('para'); //获得特定元素的数组
foreach($nodes as $node) { //循环显示
echo $node->tagName; //打印节点名称
echo "<br>";
}
?>
≶/pre>
运行后得到的结果如下:
para para para para
从结果中可以知道,这段代码将示例文档中的所有“para”节点都读取出来了。
15.4.3 取得节点内容
在得到需要的节点以后,可以使用DOM节点的“nodeValue”属性来取得节点内容,这时只需要在上一个例子中稍作修改就可以,代码如下:
<pre>
<?php
$doc = new DOMDocument(); //创建DOMDocument对象
$doc->load("15-2.xml"); //载入15-2.xml文档
$nodes = $doc->getElementsByTagName('para'); //获得特定元素的数组
foreach($nodes as $node) { //循环显示
echo $node->nodeValue; //打印节点内容
echo "<br>";
}
?>
≶/pre>
运行后得到的结果如下:
什么是HTML 什么是XML XML元素必须有结束标记 XML元素必须正确地嵌套
从结果中可以知道,这段代码将示例文档中的所有“para”节点的内容都读取出来了。
注意 使用DOM库读取XML文档后,得到的内容都会被转成UTF-8格式的编码,所以在显示的时候需要选择相应的格式。
15.4.4 取得节点属性
如果要取得节点属性,需要用到DOM元素的getAttribute()方法。对该方法传入节点属性的名称,就可以返回其属性值。还是以“15-2.xml”文档为例子,提取“prod”节点的“media”属性,代码如下:
<pre>
<?php
$doc = new DOMDocument(); //创建DOMDocument对象
$doc->load("15-2.xml"); //载入15-2.xml文档
$nodes = $doc->getElementsByTagName('prod'); //获得特定元素的数组
echo $nodes->item(0)->getAttribute('media'); //取第一个元素的media属性
?>
≶/pre>
运行后得到的结果如下:
paper
从以上代码可以看到使用getElementsByTagName()方法来得到节点列表,然后调用item(0)这个方法得到第一个节点,最后再调用getAttribute()方法得到相应的属性值。
注意 PHP的DOM库同样提供getElementById()方法来取得某个含有id属性的元素,但是这时需要DTD文件的配合。
15.5 典型实例
【实例15-1】使用DOM库读取新闻列表。
本实例提供一个使用DOM库读取新闻列表的例子。这里以新华网的新闻RSS列表(http://www.xinhuanet.com/world/news_world.xml)为范例,在浏览器中打开网页,如图15.7所示。
图15.7 新华网RSS
首先将这个RSS下载下来(便于查看原格式),保存成XML文件;使用文本编辑器查看结构,大概会是如图15.8所示的结构。
图15.8 新华网RSS结构
有了RSS地址和结构以后就可以对其中的数据进行读取,下面的例子是对这个RSS的数据进行读取并显示,如代码15-4所示。
代码15-4 对RSS的数据进行读取并显示
<span class="kindle-cn-bold">读取新浪新闻RSS</span><hr />
<pre>
<?php
$doc = new DOMDocument(); //创建DOMDocument对象
$doc->load("http://www.xinhuanet.com/world/news_world.xml"); //载入RSS文档
$nodes = $doc->getElementsByTagName('item'); //获得特定元素的数组
foreach($nodes as $node) {
//读取标题
echo "标题:" . trim($node->getElementsByTagName('title')->item(0)->nodeValue) . "<br />";
//读取链接
echo "地址:" . $node->getElementsByTagName('link')->item(0)->nodeValue . "<br />";
//读取出处
echo "出处:" . $node->getElementsByTagName('author')->item(0)->nodeValue . "<br />";
echo "<hr />";
}
?>
≶/pre>
此处代码与使用SimpleXML处理RSS新闻的步骤是类似的。首先创建DOM对象,然后使用load()方法载入RSS新闻列表。与上个例子不同的是,在读取数据时的操作会比较多。此后就可以使用循环函数将需要读取的节点读出,图15.9所示就是运行以上代码后得到的结果。
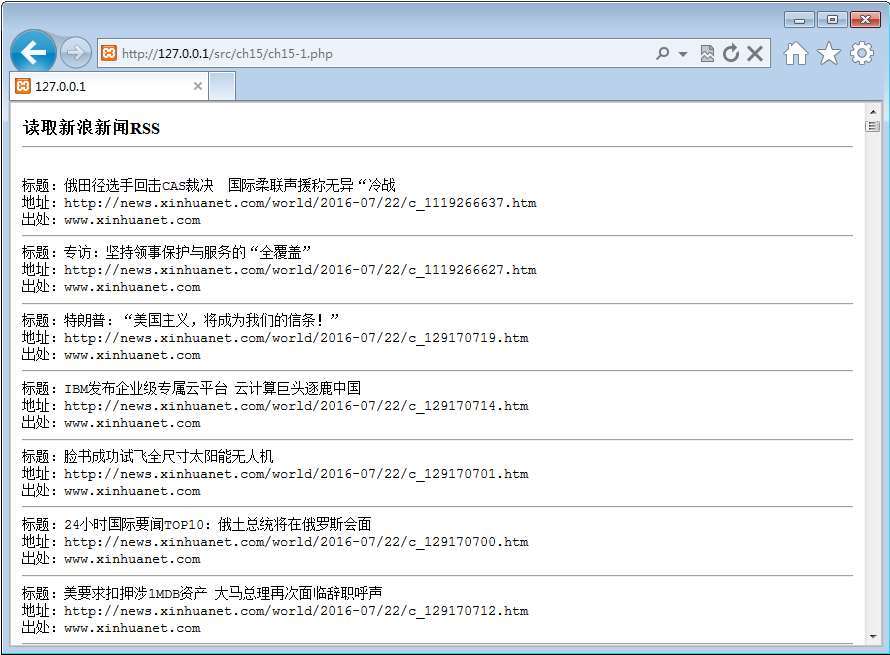
图15.9 读取RSS后的结果
【实例15-2】本实例演示如何创建XML文件。
为了方便使用,首先创建XML的代码组织成类,保存到xml.php文件中,xml.php文件中的代码如下所示。
代码15-5 创建XML文件
<?php
class xml{
var $_char = "utf-8"; //设置默认字符集
var $_charset = "<?xml version=\"1.0\" encoding=\"{char}\" ?>";
var $_root = "root"; //设置根结点名称
var $_xml = ""; //用于存储XML内容的变量
//初始化字符集变量
function xml($char="utf-8"){
$this->_char = $char;
}
//插入一条记录
function insert($line){
if(is_array($line)){ //检查插入的记录是否是数组
$xml = "<items>";
foreach($line as $k=>$v){ //遍历XML内容
$xml .= "<".$k.">".$v."</".$k.">"; //为XML文件添加新内容
}
$xml .= "</items>";
$this->_xml .= $xml;
}
}
//设置要标签
function setRoot($root){
$this->_root = $root; //返回XML文件的根结点名称
}
//取得XML内容
function getContents(){
//取得字符集设置字符
$charset = str_replace("{char}",$this->_char,$this->_charset);
//使用字符集、根结点、XML数据组成完整的XML内容
$this->_xml = $charset."<".$this->_root.">".$this->_xml."</".$this->_root.">";
return $this->_xml;
}
}
?>
在编写完xml类后,就可以在程序中使用了。本实例的代码演示xml类创建XML文件的方法。
代码15-6 xml类创建XML文件的方法
<?php
include("xml.php"); //引用XML类
//定义两个数组
$student1 = array("name"=>"小郑","age"=>22,"job"=>"计算机");
$student2 = array("name"=>"小林","age"=>23,"job"=>"计算机");
//初始化xml类,并设置字符集为gb2312
$xml = new xml("gb2312"); //初始化XML类
$xml->insert($student1); //向XML文件中插入记录
$xml->insert($student2); //向XML文件中插入记录
$x = $xml->getContents(); //返回XML内容并显示
echo $x;
?>
运行该程序后,运行结果如图15.10所示。
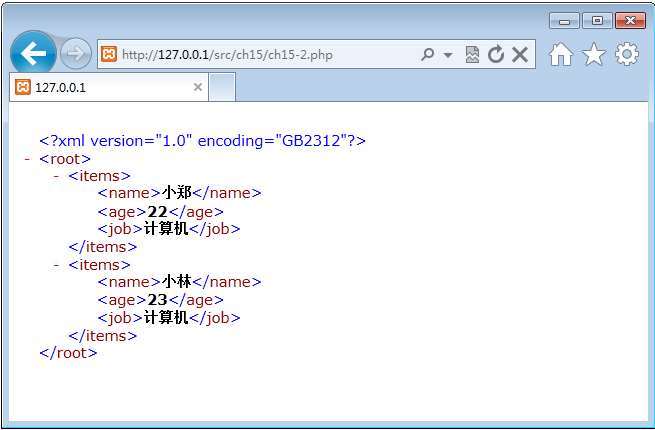
图15.10 程序运行结果
【实例15-3】读取 XML。XML文件的最基本功能是用于数据交换,本实例将在上一实例的基础上,完善xml类的功能,扩展xml类实现读取XML文件的功能。
PHP提供了专门的XML解析函数,使用这些专门的XML解析函数,可以将XML映射成HTML,或解析为数组,供其他程序使用。
PHP中可以解析的XML函数有很多种,Pear扩展库中也提供了解析XML的函数。这些XML解析函数,基本上都以SAX和DOM为基础。使用SAX方法的函数解析XML速度快,但是要对不同结构的XML文件,需要创建不同的解析函数;而DOM是通过底层的操作来解析XML,这种情况下就需要编写更多的代码,来实现XML文件的解析。
本实例将使用SimpleXML相关函数,解析XML文件。有兴趣的读者,可以参考相关资料,使用PHP相关函数,创建自定义的XML解析类。
为了方便使用,本实例将读取的XML代码放在xml类中,修改上例的xml.php文件,添加如下所示代码。
代码15-7 修改xml.php文件
<?php
class xml{
……
//解析XML内容
function parse($xmlFile){
if(function_exists("simplexml_load_file")){ //检查simplexml_load_file()函数是否存在
$xml = simplexml_load_file($xmlFile); //使用simplexml_load_flie()函数读取XML
}elseif(function_exists("file_get_contents")){ //检查file_get_contents()函数是否存在
$xml = file_get_contents($xmlFile); //使用file_get_contents()函数读取XML
$xml = new SimpleXMLElement($xml); //使用SimpleXMLElement()类解析XML
}elseif(function_exists("fopen")){ //检查fopen()函数是否存在
$handle = fopen($xmlFile,"r"); //使用fopen()获取XML文件内容
$xml = "";
while(!feof($handle)) { //使用while循环读取XML文件
$xml .= fread($handle, 8192);
}
fclose($handle);
$xml = new SimpleXMLElement($xml); //使用SimpleXMLElement()类解析读取的XML内容
}else{
$xml = false;
}
return $xml;
}
……
}
?>
在修改完xml类后就可以在程序中使用了,下面的代码演示了xml类读取XML文件的方法。
代码15-8 读取XML文件
<?php
include("xml.php"); //引用XML类
$xmlFile = "test.xml"; //设置要解决析XML文件
$xml = new xml("gb2312"); //实例化XML类
$xml_content = $xml->parse($xmlFile);//使用parse()方法,解析XML文件
xmlTable($xml_content); //使用xmlTable()显示XML内容
nodecodeTable($xml_content); //使用nodecodeTable()函数,显示XML内容
function xmlTable($content){
include("charset.php"); //引用字符编码处理类
$char = new Charset(); //实例化字符处理类
$header = "<tr><th>姓名</th><th>年龄</th><th>工作</th></tr>";
$body = "";
foreach($content as $k=>$v){ //遍历数组
$body .= "<tr><td>".$char->utf82gb($v->name)."</td><td>".$char->utf82gb($v->age)."</td><td>".$char->utf82gb($v->job)."</td></tr>";
}
echo "<table border=1>".$header.$body."</table>"; //显示表格内容
}
function nodecodeTable($content){
$header = "<tr><th>姓名</th><th>年龄</th><th>工作</th></tr>"; //设置表格显示头部内容
$body = "";
foreach($content as $k=>$v){ //遍历数组
$body .= "<tr><td>".$v->name."</td><td>".$v->age."</td><td>".$v->job."</td></tr>";
}
echo "<table border=1>".$header.$body."</table>"; //显示数组
}
?>
运行该程序后,运行结果如图15.11所示。
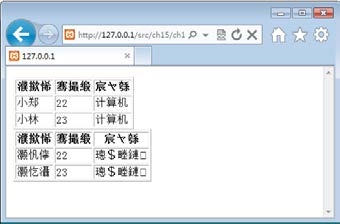
图15.11 程序运行结果
15.6 小结
对于XML的应用总有许多夸大之处和混淆之处。但是,XML并不像想象的那么难,特别是在PHP这样优秀的语言中。在理解并正确地实现了XML之后,就会发现有许多强大的工具可以使用。XPath和XSLT就是这样两个值得研究的工具。
15.7 习题
一、填空题
1. XML是一种_____语言,以结构化的方式描述各种类型的数据。
2. XML声明语句从_____开始,到_____结束。
3. DTD是一种保证XML文档格式正确的有效方法,可以通过比较_____文档和_____文件来查看文档是否符合规范,元素和标签使用是否正确。
4. 所谓有效的XML文档是指通过了_____的验证的,具有良好结构的XML文档。
5. PHP主要提供两个类用来操作XML文件,一个是_____,另一个是_____。
二、选择题
1. 关于XML以下叙述中哪个为真?( )。
A. XML是基于文本的标记语言,提供存储数据的预定义标签。
B. XML是一种平台中性的数据交换格式。
C. XML的数据交换需要VAN。
D. XML允许指出关于数据的格式化指令。
2. 以下代码片段中哪个被认为是结构良好的?( )。
A. <EMPLOYEE empid=e001>
<EMPNAME>Alice Peterson</EMPNAME>
<BASICPAY>$2000</BASICPAY>
</EMPLOYEE>
B. <EMPLOYEE empid=”e001”>
<EMPNAME>Alice Peterson<BASICPAY>$2000</EMPNAME>
</BASICPAY>
</EMPLOYEE>
C. <EMPLOYEE empid=”e001”>
<EMPNAME>Alice Peterson<BASICPAY>$2000</BASICPAY></EMPNAME>
</EMPLOYEE>
D. <EMPLOYEE empid=”e001”>
<EMPNAME>Alice Peterson<BASICPAY>$2000</BASICPAY></EMPNAME>
</employee>
3. 关于属性的以下叙述中哪个为真?( )。
A. 用属性标记XML文档中的数据。
B. 属性是用来标识和描述存储在XML文档中的数据的基本单位。
C. 属性是与数据块关联的名。
D. 属性提供了其声明的元素的信息。
三、简答题
1. XML是什么,它与HTML有什么区别?
2. XML文档由哪些部分组成?
3. 什么是XML文档中的元素,什么是元素的属性,请举例说明。