第7章 网站中的数据源——数据库与SQL基础
本章视频教学录像:1 小时9分钟
在ASP.NET网站开发中,要想在网站上能够显示动态更新的数据,网站与数据库的连接必不可少,可见数据库占有一个重要的地位。而操作数据库,就需要使用SQL语言。
本章我们就来学习数据库与SQL语言的基础知识。
本章要点(已掌握的在方框中打钩)
□ 数据库概述
□ SQL Server 2008 安装、搭建与基本操作
□ SQL 语言入门
□ SQL 查询语句
□ SQL 连接查询
□ SQL 常用函数
7.1 数据库概述
本节视频教学录像:6分钟
从计算机流行以来,数据的存储便一直是个问题。数据最早是存储在一个个文本文件中,后来由于安全、性能、灵活性等等原因,数据存储技术不断发展,日新月异,数据库技术便由此诞生。数据库技术经历网状数据库、层次数据库之后,最终形成了如今的关系型数据库的局面,而关系型数据库管理系统(DBMS)的代表有:Microsoft SQL Server系列、Oracle 系列、MySQL、DB2等。其中Microsoft SQL Server(简称MSSQL)又因其部署简单、成本低廉、性能优异、安全性能良好、与Visual Studio无缝集成等原因,成为了.NET平台必须掌握的技术。
7.1.1 关系型数据库
关系型数据库管理系统,首先管理的是一个个独立的数据库,然后将各种复杂的数据以各种相关联的表格的形式存储在不同的数据库中,解决了一系列数据方面的问题。因此,我们如今的数据库技术,便是依次对数据库、表格、数据等的管理。
在关系型数据库发展一段时间之后,为了实现数据库操作,各个厂商提供了各种数据库操作语言,曾经一度导致学习数据库语言成为程序员的“痛”,为此各厂商一起努力制定出了一套结构化数据库操作语言(Structured Query Language),便是如今的SQL。由于语言的统一,导致各个程序员入手数据库的成本大大降低。但后来由于各个数据库厂商的竞争和数据库技术的发展,标准的SQL语言已经不能满足越来越高的数据库操作要求和越来越丰富的数据库功能,因此各厂商在支持标准SQL的基础上,开始定义自己的一些语法。但是各个数据库厂商都支持标准的SQL语法及常用函数。
7.1.2 数据库基本对象简介
在介绍SQL Server 2008之前,我们首先介绍关系数据库里面的基本对象。本节内容不必死记硬背,可以参照本节去学习下一节。
数据库常见基本对象有以下几种。
1. 表(TABLE)
在SQL中,一个关系对应一个表。关系就是表中数据之间存在的联系。从直观的角度看,表就是一个二维的填有数据的表格。比如下面就是一个表。
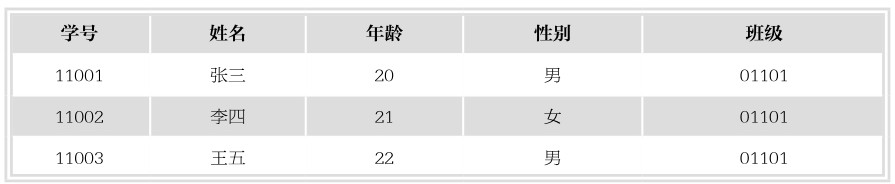
表的一行称为一个记录,表的一列称为一个字段。
2. 视图(VIEW)
视图是从一个或几个表导出的,外观和表类似。但是它和表又有所不同。表里面存储数据,而视图本身不存储数据。视图里面的数据仍然存放在表中,数据库里面存放的是视图的定义。
视图可以从一个或几个表中导出,也可以从一个或几个视图中导出。视图和表都对应着关系。
3. 索引(INDEX)
索引是用来快速访问表的,通过索引不必扫描整张表就能够查询到数据,优化了查询速度。一个表可以有若干个索引。
4. 主键(PRIMARY KEY)
表中的数据必须有唯一性,这样才能够确保查找到表中的记录。一个记录就是表中的一行数据。主键的作用就是确保这种唯一性。例如,在上面的那个表中,学号这一列就是主键,因为它是唯一的,每个学号对应一个人。通过学号可以找到每个人,而不会引起歧义。一般每个表都要定义一个主键,但不是强制的。
5. 外键(FOREIGN KEY)
如果有两个表,这两个表的主键是一样的,那么这两个表之间就可以通过相同的主键建立起关系,就可以在两个表之间查询数据。一个表的主键相对于另一个表就是外键。
7.2 数据库的搭建——SQL Server 2008
本节视频教学录像:14分钟
在学习SQL语言前,我们先学习安装SQL Server 2008。这是随Visual Studio 2010一起发布的数据库管理系统。
其实,在安装Visual Studio 2010时会顺便安装一个Express版的SQL Server,这个SQL Server只能通过Visual Studio 2010集成的数据库管理功能进行管理,不能通过SQL Server本身的管理工具进行管理。
本节以SQL Server 2008标准版为例进行安装讲解。
7.2.1 安装SQL Server 2008
安装SQL Server 2008的具体步骤如下。
⑴插入SQL Server 2008安装光盘,运行安装程序,稍等片刻,便可进入【SQL Server安装中心】界面,单击左侧的【安装】,然后在右侧单击【全新SQL Server独立安装或向现有安装添加功能】。
⑵进入【安装程序支持规则】界面,安装程序开始检测计算机是否支持安装SQL Server 2008,检测全部通过后,单击【确定】按钮。
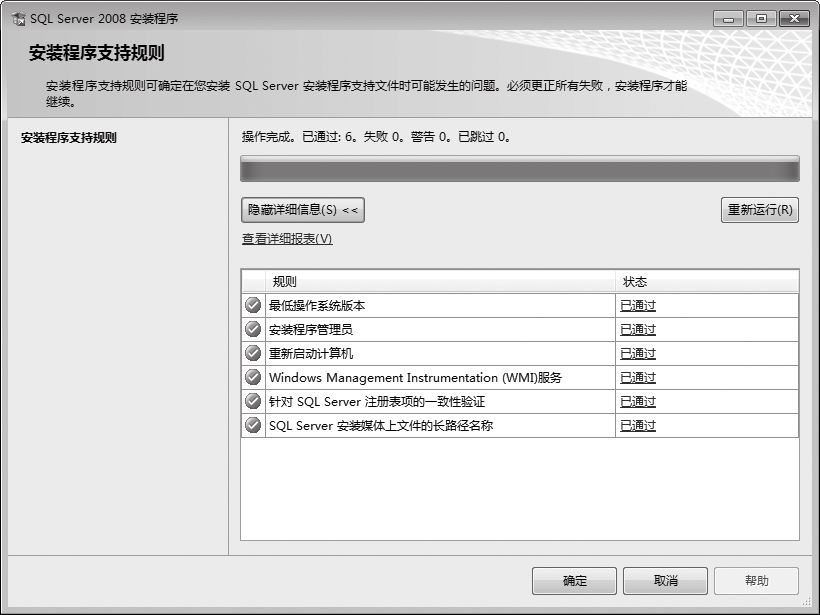
⑶进入【安装程序支持文件】界面,单击【安装】按钮,开始安装程序支持文件。
⑷安装完成自动跳转到SQL Server 2008安装配置阶段,如果检测全部通过,单击【下一步】按钮。
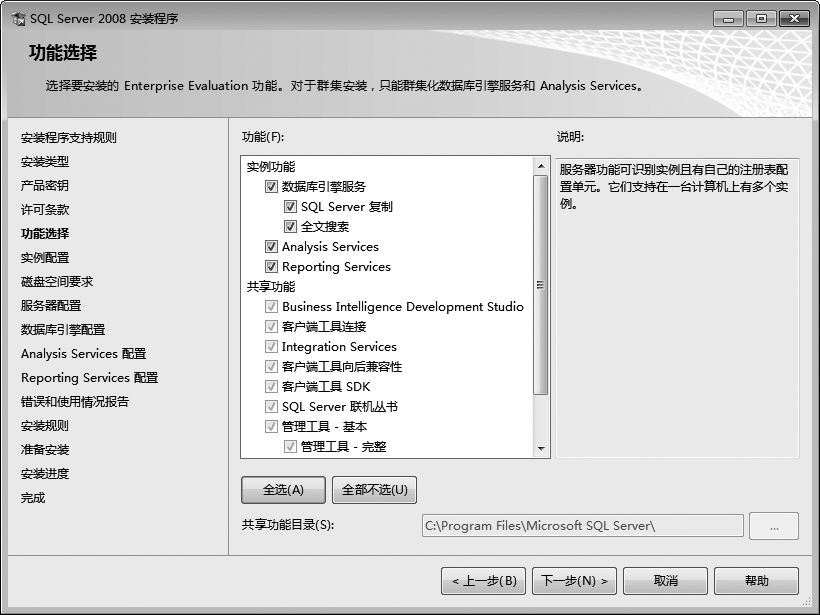
⑸进入【产品密钥】界面,在此处需要选择安装的版本、输入产品密钥,单击【下一步】按钮,继续安装程序支持文件,完成后自动转向【功能选择】界面,在此界面中选择需要的功能或全部选择,单击【下一步】按钮。
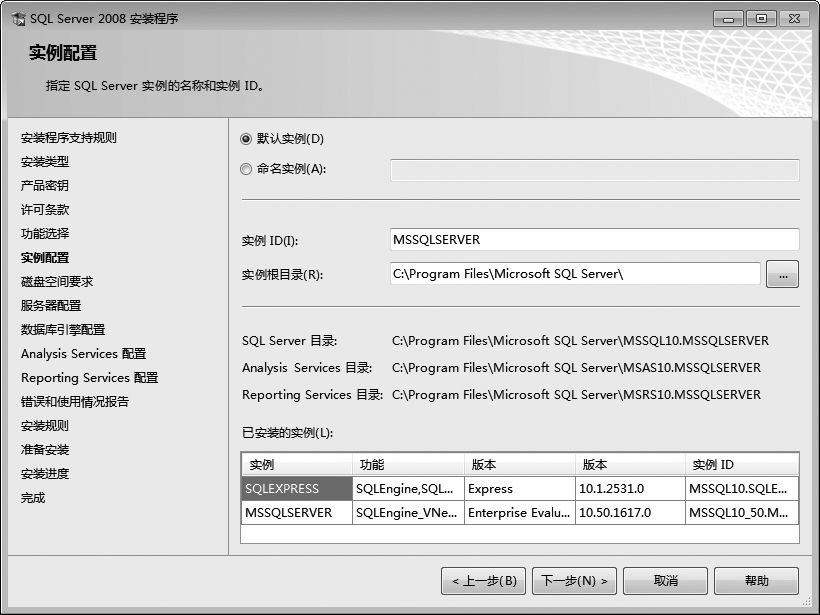
⑹进入【实例配置】界面,选择SQL Server实例名,此处选择默认选项,也可以自己命名。
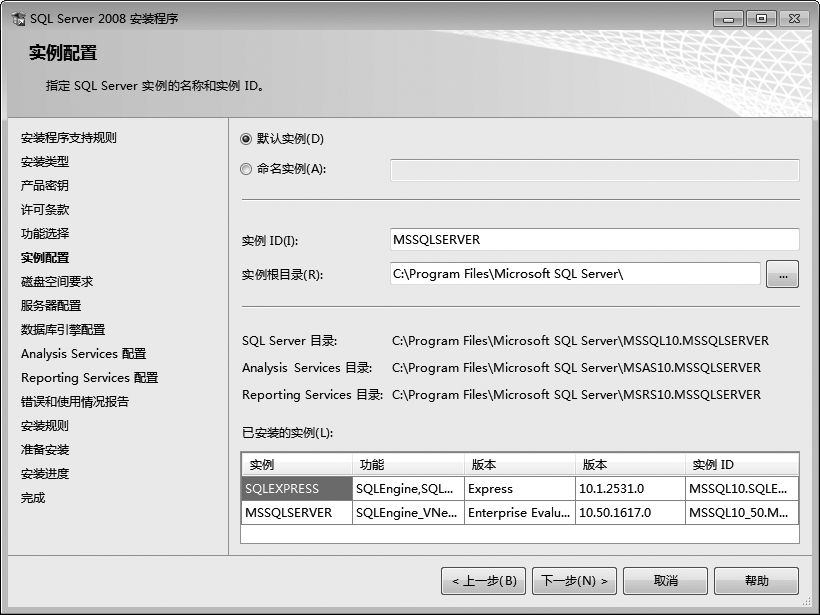
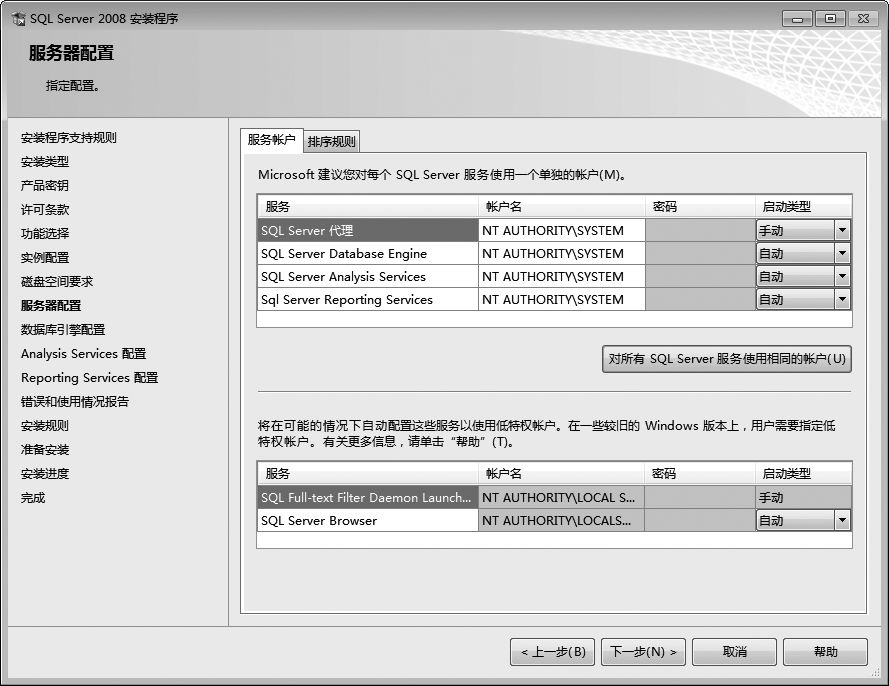
⑺单击【下一步】按钮,检测所选安装驱动器的剩余空间是否符合要求,然后单击【下一步】按钮,进入【服务器配置】界面,开始设置服务的权限。在【SQL Server Database Engine】后面的账户名中选择计算机中的当前账户。如果数据库要求网络上的机器也可以访问,可以将所有账户名设置为【NT AUTHORITY\NETWORK SERVICE】。
⑻单击【下一步】按钮,进入【数据库引擎配置】界面,选择【混合模式】,并设置密码(SQL Server中默认的超级管理员用户名是sa,这里设置密码为123),然后单击【添加当前用户】按钮。
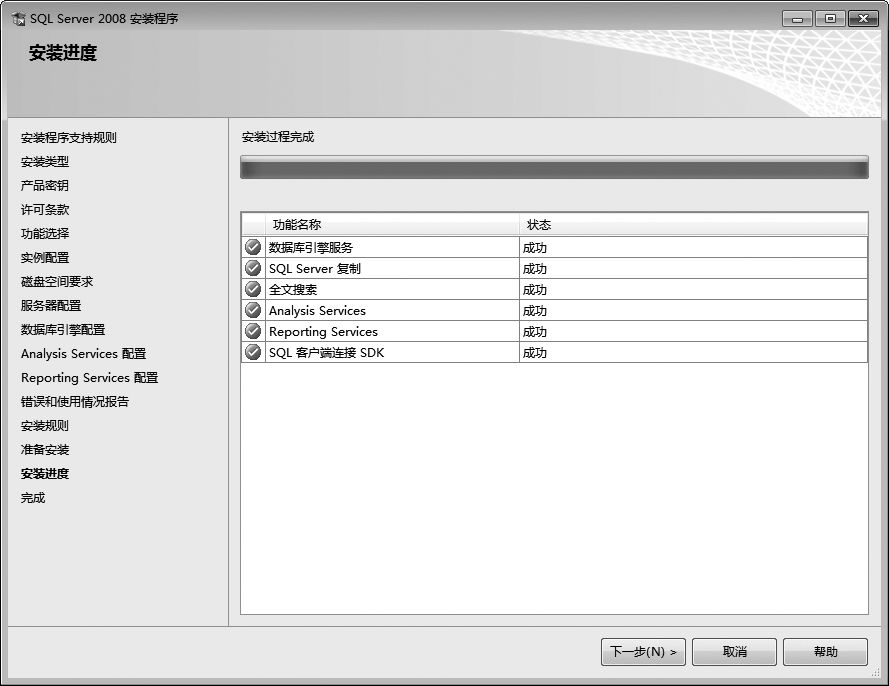
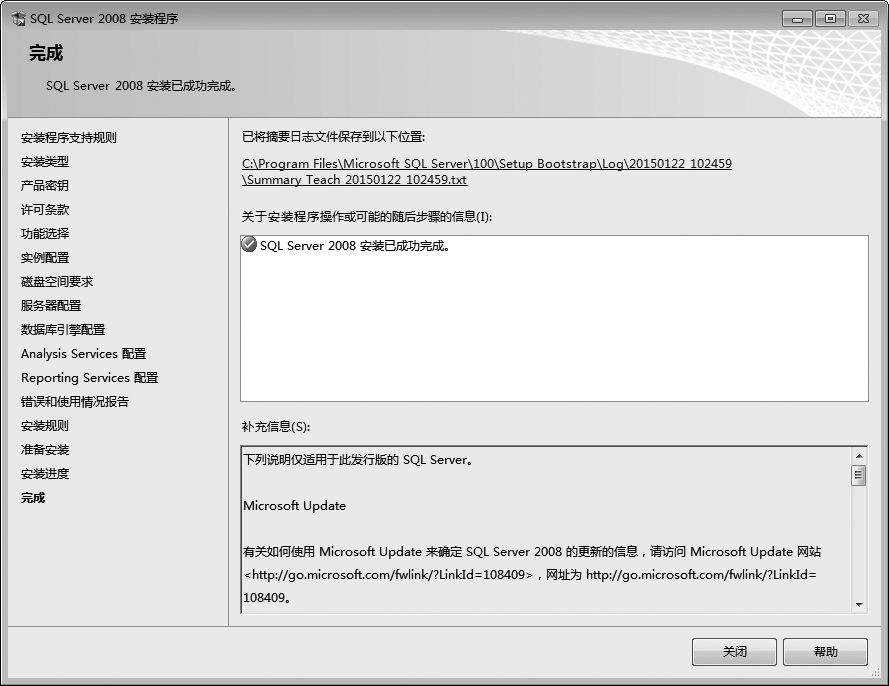
⑼根据提示一直单击【下一步】按钮,开始安装SQL Server 2008,并显示安装进度。
⑽安装完成后,单击【关闭】按钮,即可成功安装SQL Server 2008。
提示
安装Visual Studio 2010时会默认安装SQL Server 2008 Express版本,这是SQL Server的一个快捷版本,默认没有图形管理工具,可以通过微软网站下载一个SQLManagementStudio的图形管理工具并安装,主要区别在于Express版的服务器名称是“.\sqlexpress”,而企业版的可以直接用“.”。
7.2.2 启动SQL Server 2008
启动SQL Server 2008的具体步骤如下。
⑴打开开始菜单,选择【开始】 【所有程序】
【所有程序】 【Microsoft SQL Server 2008】
【Microsoft SQL Server 2008】 【SQL Server Management Studio】,出现登录界面。
【SQL Server Management Studio】,出现登录界面。
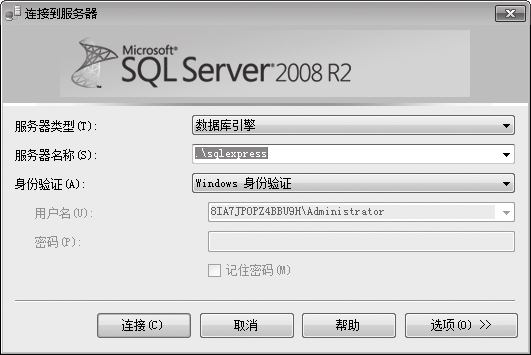
⑵在【身份验证】下拉列表中,如果选择【Windows 身份验证】选项,则默认使用当前登录用户登录SQL Server 2008。
⑶选择【SQL Server身份验证】选项,则填写登录名sa和安装时设置的密码sa123,然后单击【连接】按钮。
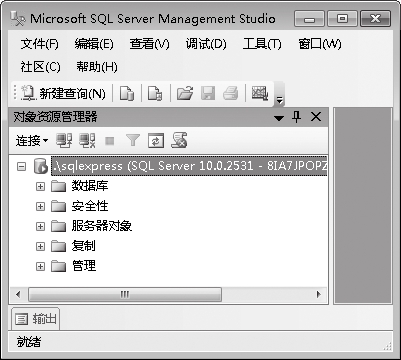
⑷连接后,即可出现SQL Server 2008的管理器界面。
7.2.3 数据库基本操作
学习SQL语言前,我们先通过SQL Server Management Studio提供的可视化工具来熟悉数据库的基本操作。
1. 新建数据库
在SQL Server 2008中,新建数据库的具体步骤如下。
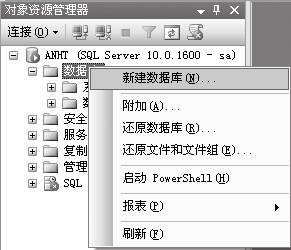
⑴右击【对象资源管理器】,从弹出的快捷菜单中选择【新建数据库】菜单项。
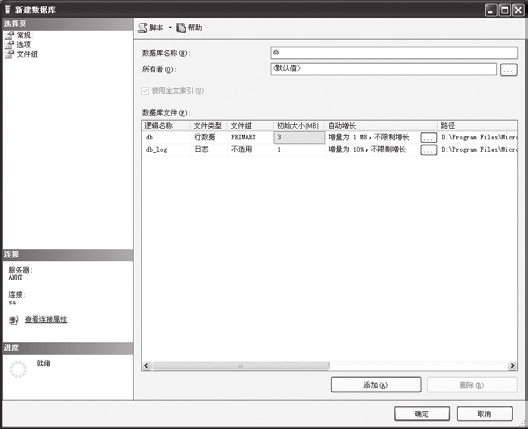
⑵在弹出的【新建数据库】对话框中,填写数据库名称、设置数据库文件后,单击【确定】按钮,即可新建1个数据库文件。
⑶新建的数据库文件会添加到【对象资源管理器】中。
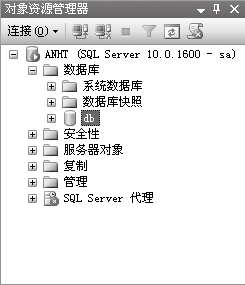
2. 新建数据表
⑴在【对象资源管理器】中展开需要创建表的数据库,右击【表】,在弹出的快捷菜单中选择【新建表】菜单项。
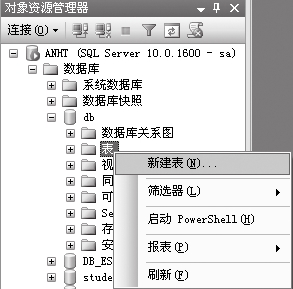
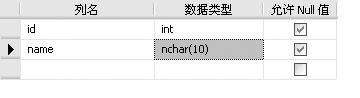
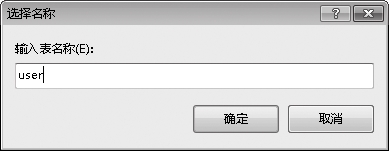
⑵在中间的编辑窗口中,输入列名和数据类型,按【Ctrl+S】组合键,在弹出的【选择名称】对话框中输入表名,单击【确定】按钮,刷新后即可显示。
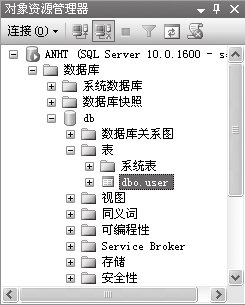
3. 编辑数据
⑴在表名上右击,在弹出的快捷菜单中选择【编辑前200行】菜单项。
⑵在中间的编辑窗口中输入数据即可。
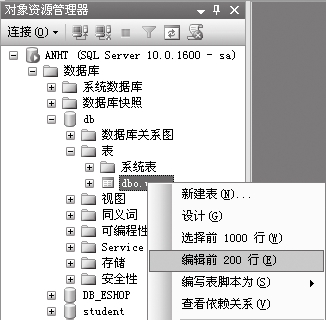
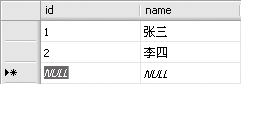
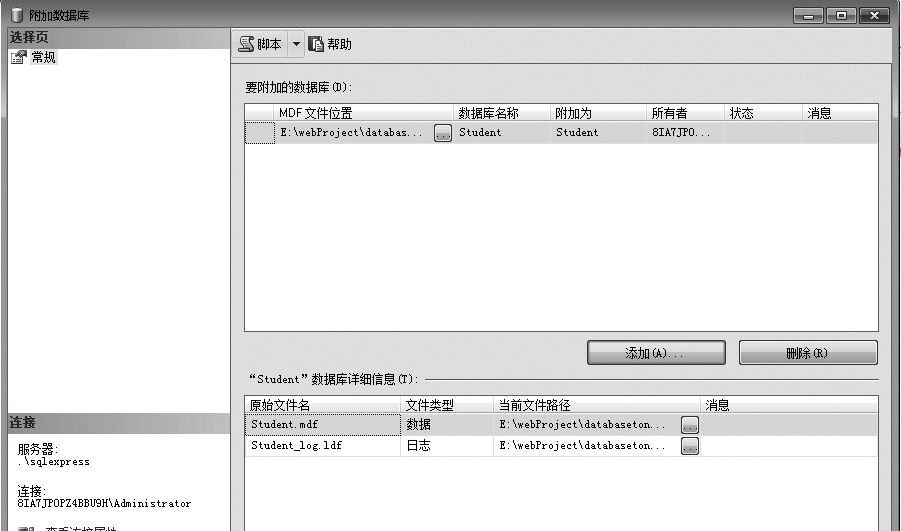
4. 附加数据库
在SQL Server 2008中,附加数据库的具体步骤如下。
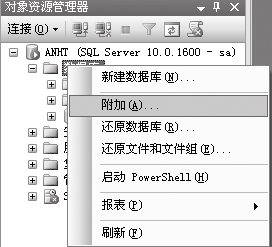
⑴在【对象资源管理器】上右击,选择【附加】。
⑵弹出的【附加数据库】对话框,单击【添加】按钮,浏览到数据库文件处,单击【确定】按钮,即可出现下图所示界面。
⑶单击【确定】按钮,即可附加数据库,并出现在【对象资源管理器】中。
7.3 SQL语言入门
本节视频教学录像:14分钟
SQL(Structured Query Language,结构化查询语言)是一种数据库查询语言。不过它的功能绝非仅限于查询,还可以创建、修改、删除、更新数据库,完成数据的查询、排序、插入、删除等功能。它是关系型数据库管理系统的标准语言。
现在使用的主流数据库都是关系型数据库,像Oracle、SQL Server、Sybase、Access等,都是把SQL语言作为数据库操作的标准语言。
SQL语言包括3种主要程序设计语言类别的陈述式:数据定义语言(DDL)、数据操作语言(DML)及数据控制语言(DCL)。
SQL语言包含以下4个部分。
⑴数据定义语言(DDL),例如:CREATE、DROP、ALTER等语句。
⑵数据操作语言(DML),例如:INSERT(插入)、UPDATE(修改)、DELETE(删除)等语句。
⑶数据查询语言(DQL),例如:SELECT语句。
⑷数据控制语言(DCL),例如:GRANT、REVOKE、COMMIT、ROLLBACK等语句。
7.3.1 创建数据库CREATE DATABASE
首先我们创建一个数据库,有了数据库才能进行数据库操作,语法如下。
CREATE DATABASE 数据库名
[可选参数……]
很简单,后面还可以带一些可选的参数。如果不带参数,系统就会设为默认值。这些参数很复杂,读者也没有必要全部掌握它们,只要在实际应用过程中多动手就会清楚了。下面通过几个实例说明。
【范例7-1】创建一个student数据库。
⑴在SQL Server 2008中,以sa账户登录。
⑵单击工具栏中的【新建查询】按钮,在右侧窗口中输入以下代码。
CREATE DATABASE student
⑶单击工具栏中的【!执行】按钮,右边下面的消息框会提示“命令已成功完成”。
⑷右击【对象资源管理器】中的【数据库】,选择【刷新】后,即可出现“student”数据库。
【拓展训练7-1】
创建一个student2数据库,指定数据文件所存放的地方。新建查询,并输入以下代码。
CREATE DATABASE student
ON
(
NAME='student2',
FILENAME='D:\student2.mdf'
)
执行后,即可在指定位置新建名为“student2”的数据库。我们可以看到文件夹里面有两个文件,一个是student.mdf,这是个数据库文件;另一个是student_log.ldf,这是个日志文件。
7.3.2 删除数据库DROP DATABASE
如果不需要数据库了,可以将它删除。删除语句的语法如下:
DROP DATABASE 数据库名
如删除student数据表,可在新建查询中输入以下代码。
DROP DATABASE student
7.3.3 创建表CREATE TABLE
创建了数据库以后,就可以在里面创建表。创建表语句的语法如下:
CREATE TABLE 表名
(
字段名 字段数据类型 [可选约束],
字段名 字段数据类型 [可选约束],
……
)……
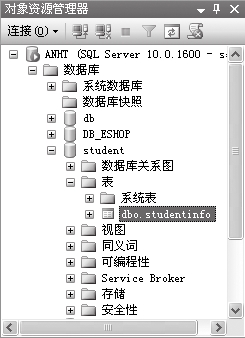
【范例7-2】在【范例7-1】建立的student数据库中创建一个名为studentinfo的表。
⑴在【对象资源管理器】中单击【student】,单击工具栏中的【新建查询】按钮。
⑵在右侧窗口中输入以下代码。
CREATE TABLE studentinfo
(
id int,
name nvarchar(50),
age int
)
⑶执行、刷新后,即可创建名为“studentinfo”的表。
⑷在表名上右击,选择【设计】,即可在右侧窗口中浏览表的结构。这个表有3个字段,也就是3列,分别是id(学号)、name(姓名)和age(年龄),数据类型分别是int、nvarchar和int。
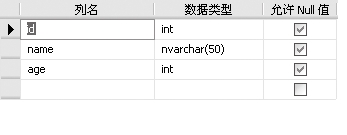
7.3.4 修改表ALTER TABLE
在表创建完后,就可以按照自己的要求修改表。修改表的语句为ALTER TABLE,下面我们通过例子来学习表的修改。
例1:将【范例7-1】中studentinfo表的name字段改为nvarchar(10),非空,代码如下。
ALTER TABLE studentinfo
alter column name nvarchar(10) not null
例2:在例1的基础上添加一个gender字段,数据类型为nvarchar(2),非空,代码如下。
ALTER TABLE studentinfo
add gender nvarchar(2) not null
例3:把例2中添加的字段删除,代码如下。
ALTER TABLE studentinfo
drop column gender
例4:对gender字段添加约束,让它只能是“男”或“女”,代码如下。
ALTER TABLE studentinfo
add constraint ck_gender check(gender='男' or gender='女')
其中constraint代表约束,ck_gender是约束名。Check后面的括号里是约束条件。
7.3.5 删除表DROP TABLE
删除表也很简单,语法如下:
DROP TABLE 表名
例:删除表studentinfo,代码如下。
DROP TABLE studentinfo
这样就删除了前面创建的studentinfo表。
7.3.6 插入数据INSERT
INSERT语句用于将新行追加到表中。语法如下。
INSERT INTO 表名[(字段列表)] values (值列表)
下面通过几个例子来学习插入数据操作。
例1:在studentinfo表里插入张三的信息,代码如下。
INSERT INTO studentinfo values (11001,'张三',20,'男')
这个表里面有4个字段,这里依次为每一个字段制定了值,因此不必再制定字段名,但是要保证与字段的数据类型一一对应。values通常与INSERT一起使用,values后面的括号里是要插入的各字段的值,用逗号分开。
例2:在studentinfo表里插入李四的信息,代码如下。
INSERT INTO studentinfo
(name,id,gender,age)
values ('李四',11002,'女',21)
和上个例子不同的是,这里不是按字段在表里的顺序插入的。所以要列出字段,与下面要插入的值一一对应。也可以只插入部分字段的值,剩下的可以为空的字段和自动增长的字段自动设为默认值。但是非空字段一定要插入值。
7.3.7 更新数据UPDATE
UPDATE语句可以用来更新表里的数据,语法如下。
UPDATE 表名
set 新值
[where 条件]
其中[ ]里面是可选的。UPDATE可以同时更改多个字段。
例1:将studentinfo表里的张三的年龄加1,代码如下。
UPDATE studentinfo
SET age=age+1
WHERE name='张三'
例2:将studentinfo表里姓名为张三的年龄改为22,新建查询代码如下。
UPDATE studentinfo
set age=22
where (name='张三')
UPDATE通常和SET以及WHERE一起使用。SET后面是修改表达式,WHERE后面是要修改的条件。要注意的是,UPDATE语句一次可以更新多条记录。上面的例子中,如果去掉where后面的语句,将会把所有人的年龄都改为22。
7.3.8 删除数据DELETE
DELETE用来从表中删除记录。语法如下。
DELETE [from] 表名 [where 条件]
其中[ ]里面的内容是可选的。
例1:将studentinfo表里姓名为张三的记录删除,代码如下。
DELETE studentinfo
where name='张三'
和UPDATE类似,DELETE一次可以删除多条记录。如果没有WHERE子句,将会删除所有记录。
例2:从前面的雇员信息表里面删除所有年龄大于55岁的雇员信息,新建查询代码如下。
DELETE FROM 雇员信息
WHERE 年龄>55
例3:从前面的通讯录里面删除所有姓王的人的信息,代码如下。
DELETE FROM 通讯录
WHERE 姓名LIKE '王%'
例4:删除通讯录里面所有记录,代码如下。
DELETE FROM 通讯录
7.4 SQL查询语句
本节视频教学录像:9分钟
SELECT语句用于数据库查询,是SQL语言里面最复杂、最灵活也是最有用的语句。学好SELECT语句是学好SQL语言的关键。与SELECT配合使用的还有FROM和WHERE子句。灵活地运用这些语句可以实现强大的查询功能。
虽然 SELECT 语句的完整语法较复杂,但其主要子句可归纳如下:
SELECT 查询列表 [ INTO 新表名 ]
[ FROM 表名] [ WHERE 查询条件 ]
[ GROUP BY 分组条件]
[ HAVING 搜索条件]
[ ORDER BY 排序条件 [ ASC | DESC ] ]
WHERE 子句、GROUP BY 子句和 HAVING 子句的 SELECT 语句的处理顺序以及它们的作用如下:
⑴FROM 子句返回初始结果集。
⑵WHERE 子句排除不满足搜索条件的行。
⑶GROUP BY将选定的行收集到 GROUP BY 子句中各个唯一值的组中。
⑷选择列表中指定的聚合函数可以计算各组的汇总值。
⑸HAVING 子句排除不满足搜索条件的行。
7.4.1 FROM子句
在 SELECT 语句中,FROM 子句是必需的,指定从哪些表中查询。下面举几个例子,让大家了解如何利用这些子句进行查询。
首先按照4.2.2小节中的操作,创建一个名为student的数据库,在里面创建两个表studentinfo和examscore,并添加数据,如下图所示(数据库见随书光盘\Sample\ch04\student.mdf)。
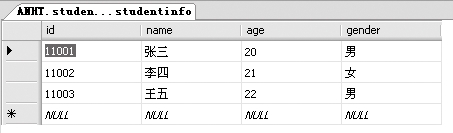
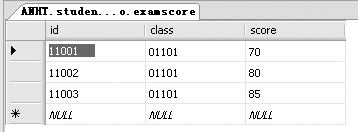
例1:查询studentinfo表里的所有记录,代码如下。
select * from studentinfo
查询结果如下:
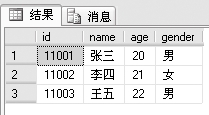
由此可见,“*”型号代表所有字段。
例2:查询studentinfo表里所有学生的学号和姓名,代码如下。
select id,name
from studentinfo
查询结果如下:
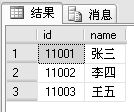
SELECT后面跟着查询列表,里面有要查询的字段名,用逗号隔开。
7.4.2 使用WHERE子句设置查询条件
WHERE子句用来指定查询条件。下面举几个例子来说明怎样使用这些子句进行查询。
例1:从examscore表里面查询分数高于80的学生的记录,代码如下。
SELECT *
FROM examscore
WHERE score>=80
查询结果如下:
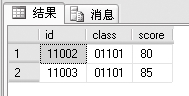
WHERE子句给出了查询条件,要求score字段的值大于或等于80。前面都是在一个表里面查询,下面举一个多表查询的例子。
例2:从studentinfo表和examscore表中查询出所有学生的成绩,要求有id、name、gender、score、class字段。查询结果按考试分数从高到低排序,代码如下。
select studentinfo.id,name,gender,score,class
from studentinfo,examscore
where studentinfo.id=examscore.id
ORDER BY score DESC
查询结果如下:
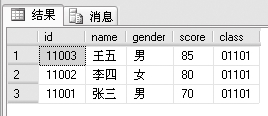
上面是一个多表查询的例子。两个表都有id字段,因此两个表可以通过id字段建立关系进行多表查询。如果一个表的id字段是主键,那么另一个表的id字段就是外键。在查询列表里面,要用“表名+‘点’+字段名”的方式表示这个两个表中相同的字段。例如studentinfo.id,WHERE后面的查询条件也如此。FROM后面列了两个表名,表示从两个表中查询,中间用逗号隔开。ORDER BY表示排序, DESC表示逆序,也就是从大到小排序。还有一个ASC表示顺序。最后一句的意思就是按照score字段从大到小排序。
7.4.3 通配符
当我们需要进行模糊查询的时候,比如查询姓王的同学的信息,就需要使用通配符,它可以模糊匹配字符或者字符串。通配符有下面几种。

比如,“张%”可以表示“张三”,“张abc”,“张冠李戴”等。通配符常常和LIKE关键字配合使用。
例如:查询studentinfo里面所有姓张的同学的信息,新建查询代码如下。
select *
from studentinfo
where name like '张%'
查询结果如下:
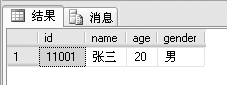
可见,通配符放在WHERE子句里面做查询条件,在LIKE后面和LIKE配合使用。最后一行代码的含义是:name字段以张开头,即查询姓名字段中以张开头的所有记录。
7.5 SQL连接查询
本节视频教学录像:11分钟
在前面7.4.2小节中,我们举了一个多表查询的例子,利用了WHERE子句设置查询条件,各表之间用逗号隔开。在SQL Server里面还有另外一种多表查询方式,我们称为连接查询。SQL Server提倡使用后者。连接查询使用JOIN…ON…语句。
连接查询的语法如下:
SELECT 参数列表
FROM 连接表一连接类型连接表二
[ON 连接条件]
可见,这里用ON代替了WHERE来表示查询条件。连接表一和连接表二表示要执行连接操作的两个表。也可以是同一个表,称为自连接。连接类型有以下几种:
⑴[INNER] JOIN 内连接
⑵LEFT [OUTER] JOIN 、RIGHT [OUTER] JOIN、FULL [OUTER] JOIN外连接
⑶CROSS JOIN交叉连接
使用不同的连接可以得到不同的查询结果。下面具体介绍这几种连接:
7.5.1 内连接
[INNER] JOIN内连接只显示符合条件的记录,是默认的方式。[ ]里面的内容可以省略。下面举一个例子说明内连接的用法。
例:从studentinfo表和examscore表中查询出所有学生的成绩和所有信息,新建查询代码如下。
SELECT *
FROM studentinfo INNER JOIN examscore
ON studentinfo.id=examscore.id
查询结果如下:
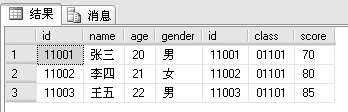
从上面的结果可以看出,INNER JOIN两边列出了要连接查询的两个表名。ON后面指明了查询条件,查询两个表中id字段匹配的记录的所有信息。
我们发现查询结果中出现了两个相同的id字段。这是不必要的。如果SELECT后面用*,则默认列出所有字段,不管是否重复。我们可以把上面的代码稍作修改,以去掉重复的字段:
SELECT studentinfo.id,name,age,gender,class,score
FROM studentinfo INNER JOIN examscore
ON studentinfo.id=examscore.id
查询结果如下:
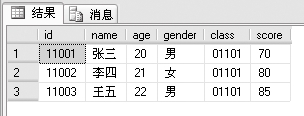
7.5.2 外连接
外连接包括3种即LEFT [OUTER] JOIN 、RIGHT [OUTER] JOIN和FULL [OUTER] JOIN。分别叫做左外连接、右外连接和全外连接。作用如下。
⑴LEFT [OUTER] JOIN:显示左边表中所有记录,以及右边表中符合条件的记录。
⑵RIGHT [OUTER] JOIN:显示右边表中所有记录,以及左边表中符合条件的记录。
⑶FULL [OUTER]:显示所有表中所有记录。
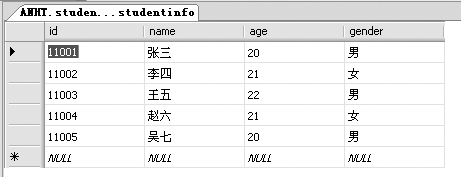
下面分别对这3种情况进行举例。在举例之前,将4.4.1小节中的表修改如下(数据库见随书光盘\Sample\ch04\student.mdf)。
studentinfo表:
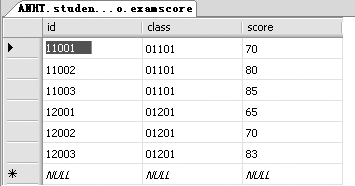
examscore表:
例1:左连接,代码如下。
SELECT *
FROM studentinfo LEFT JOIN examscore
ON studentinfo.id=examscore.id
查询结果如下:
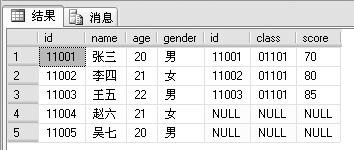
结果显示了 LEFT JOIN 左边表(studentinfo)的所有记录,和右边表里面符合查询条件(studentinfo.id=examscore.id)的记录。有意思的是,studentinfo表里面有赵六和吴七的信息, examscore表里却没有。结果里面显示它们的examscore表里的id,class和score字段为NULL,也就是空。
例2:右连接,代码如下。
SELECT *
FROM studentinfo RIGHT JOIN examscore
ON studentinfo.id=examscore.id
查询结果如下:
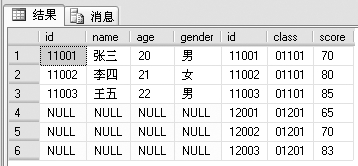
结果和例一正好相反。结果显示了LEFT JOIN右边表(examscore)的所有记录,和左边表里面符合查询条件(studentinfo.id=examscore.id)的记录。有意思的是,examscore表里面有id为12001、12002和12003的信息,studentinfo表里却没有。结果里面显示它们的studentinfo表里的id、name、age和gender字段为NULL,也就是空。
例3:全连接,代码如下。
SELECT *
FROM studentinfo FULL JOIN examscore
ON studentinfo.id=examscore.id
查询结果如下:
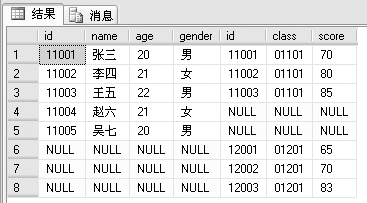
结果显示了两个表的所有记录。这正是FULL JOIN的功能。
7.5.3 交叉连接
交叉连接不带ON 子句,它返回被连接的两个表所有数据行的笛卡尔积,也就是结果集中的记录数等于第1个表中符合查询条件的记录数乘以第2个表中符合查询条件的记录数。
例如,第1个表中有5条记录,第2个表中有6条,则查询结果有30条记录。这30条是第一个表中每条记录和第2个表中每条记录组合的结果。新建查询代码如下。
SELECT *
FROM studentinfo CROSS JOIN examscore
查询结果如下,可见结果显示了30条记录。
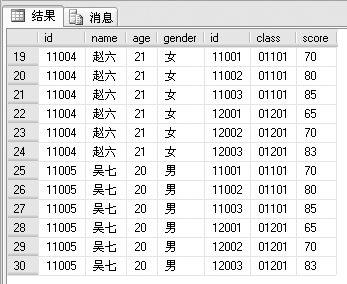
7.6 SQL常用函数
本节视频教学录像:7分钟
本节我们来学习SQL中的常用函数。
7.6.1 统计字段值的数目
使用集合函数COUNT可以统计字段值的数目。COUNT 与 COUNT_BIG 函数类似。两个函数唯一的差别是它们的返回值。COUNT 始终返回 int 数据类型值。COUNT_BIG 始终返回 bigint 数据类型值。
COUNT的语法如下:
COUNT ( { [ [ ALL | DISTINCT ] 表达式] |*} )
COUNT(*) 返回组中的项数。包括 NULL 值和重复项。COUNT(ALL表达式) 对组中的每一行都计算表达式并返回非空值的数量。COUNT(DISTINCT表达式) 对组中的非重复行计算表达式并返回唯一非空值的数量。对于大于 2^31-1 的返回值,COUNT 生成一个错误。这时应使用 COUNT_BIG。
我们使用7.5.2小节中修改后的两个表。
例1:统计studentinfo表里面的纪录数,新建查询代码如下。
SELECT COUNT (*)
FROM studentinfo
查询结果如下:
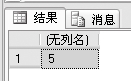
结果是5,说明里面有5条记录。
例2:统计examscore表里面的班级数,代码如下
SELECT COUNT (DISTINCT class)
FROM examscore
查询结果如下:
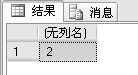
结果是2,说明里面有两个班级。DISTINCT可以避免统计重复的记录。如果把DISTINCT改为ALL,得到的结果则是6。因为统计了重复的信息。
7.6.2 计算字段的平均值
AVG返回组中各值的平均值。空值将被忽略。AVG的语法如下:
AVG ( [ ALL | DISTINCT ] 表达式)
其中DISTINCT不计算相同的值。
例:计算examscore表里面学生的平均考试成绩,代码如下。
SELECT AVG (ALL score) AS 平均成绩
FROM examscore
查询结果如下:
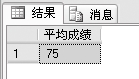
这里使用了ALL,表示计算所有学生的平均成绩。AS表示为结果字段取一个别名,AS后面的“平均成绩”就是别名。如果把ALL改为DISTINCT,则计算出的平均成绩是76。因为它忽略了重复的数据,有两个学生都是70分,却只统计了一个。
7.6.3 计算字段值的和
SUM 返回表达式中所有值的和或仅非重复值的和。SUM 只能用于数字列。空值将被忽略。SUM 的语法如下。
SUM ( [ ALL | DISTINCT ] 表达式 )
其中ALL和DISTINCT的含义同COUNT和AVG。
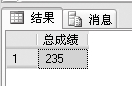
例:统计01101班所有学生的总成绩,代码如下。
SELECT SUM(ALL score) AS 总成绩
FROM examscore
WHERE class = 01101
显示的结果如下:
7.6.4 返回最大值或最小值
MAX 返回表达式的最大值。MAX的语法如下:
MAX ( [ ALL | DISTINCT ] 表达式 )
MAX 忽略任何空值。对于字符列,MAX 查找按排序序列排列的最大值。ALL和DISTINCT的含义同COUNT、AVG和SUM。
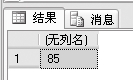
例:找出01101班的最高成绩,代码如下。
SELECT MAX(ALL score)
FROM examscore
WHERE class = 01101
查询结果如下:
MIN:返回表达式的最小值,用法同MAX,这里不再赘述。
7.7 存储过程
本节视频教学录像:5分钟
存储过程(Stored Procedure)是在数据库系统中,一组为了完成特定功能的SQL语句集,经过编译以后存储在数据库中,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程是数据库对象之一,也可以理解为数据库的子程序,在客户端和服务器端可以直接调用它,同时存储过程也可以接受输入参数,返回表格或标量结果和消息,调用“数据定义语言(DDL)”和“数据操作语言(DML)”语句,然后返回输出参数。
本节我们来学习如何在SQL Server 2008中创建和使用存储过程。
7.7.1 存储过程的创建
存储过程只能定义在当前数据库中,可以使用T-SQL命令或者“对象资源管理器”创建。使用CREATE PROCEDURE语句创建存储过程的语法如下:
CREATE PROCEDURE procedure_name [;number]
[{@parameter data_type}
[VARYING][=default][OUTPUT]][,…n]
[WITH {RECOMPILE | ENCRYPTION | RECOMPILE,ENCRYPTION }]
[FOR REPLICATION]
AS sql_statement[…n]
其主要参数含义如下:
⑴Procedure_name:新存储过程的名称。过程名称在架构中必须唯一,可在procedure_name前面使用一个数字符号“#”来创建局部临时过程,使用两个数字符号“#”来创建全局临时过程。
⑵;number:是可选的整数,用来对同名的过程分组。使用一个DROP PROCEDURE语句可将这些分组过程一起删除。
⑶@parameter:过程中的参数。在CREATE PROCEDURE语句中可以声明一个或多个参数。
⑷Data_type:参数的数据类型。所有数据类型均可以用作存储过程的参数。
⑸Default参数的默认值。如果定义了dafault值,则无须指定此参数的值即可执行过程。默认值必须是常量或NULL。
⑹Output:指示参数是输出参数。此选项的值可以返回给调用EXECUTE的语句。使用OUTPUT参数将值返回给过程的调用方。
例1:在数据库Student中创建一个名为 Reader_proc 的存储过程,它将从StudentInfo表中返回所有学生的姓名、性别、出生日期和成绩。使用CREATE PROCEDUCE 语句如下。
USE Student
GO
CREATE PROCEDURE Reader_proc
AS
SELECT Sname,Sex,Birthday,Score
FROM StudentInfo
执行结果如下:
例2:创建CountStudent存储过程,获取Student数据库中学生的总人数。
USE Student
GO
CREATE PROCEDURE proc_CountStudent
AS
SELECT count(NO) AS 总数
FROM StudentInfo
执行结果如下:
7.7.2 存储过程的执行
在需要执行存储过程时,可以使用T-SQL语句EXECUTE。如果存储过程是批处理中的第一条语句,那么不使用EXECUTE关键字也可以执行该存储过程,EXECUTE语法格式如下:
[ { EXEC | EXECUTE } ]
{
[ @return_status= ] { procedure_name [;number] |@procedure_name_var }
@parameter = [ { value |@variable [ OUTPUT ] | [ DEFAULT ] } ]
[,…n]
[ WITH RECOMPILE ]
其中主要参数的含义如下:
⑴@return_status:是一个可选的整型变量,保存存储过程的返回状态。这个变量在用于EXECUTE语句前,必须在批处理、存储过程或函数中声明过。
⑵procedure_name:要调用的存储过程名称。
⑶;number:是可选的参数,用于将相同名称的过程进行组合,使得它们可以用一句 DROP PROCEDURE 语句删除。
⑷@procedure_name_var:是局部变量名,代表存储过程名称。
⑸@parameter:是过程参数,在CREATE PROCEDURE 语句中定义。
⑹Value:是过程中参数的值。
⑺@ variable:是用来保存参数或者返回参数的变量。
⑻OUTPUT:指定存储过程必须返回一个参数。
⑼DEAULT:根据过程的定义,提供参数的默认值。
下面我们通过 EXECUTE 语句来执行7.7.1小节中创建的两个存储过程。
例1:执行第一个Reader_proc存储过程,语句如下。
USE Student
GO
EXECUTE Reader_proc
执行结果如下:
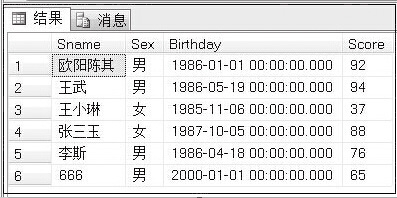
该存储过程获取了所有学生的姓名、性别、出生日期和成绩。
例2:执行第二个proc_CountStudent存储过程,语句如下。
USE Student
GO
EXECUTE proc_ CountStudent
执行结果如下:
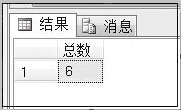
该存储过程统计了学生的总人数。
7.8 高手点拨
本节视频教学录像:3分钟
1. 常用的关系型数据库管理系统介绍。
目前常用的关系型数据库管理系统有Oracle、SQL Server、Mysql、DB2等。其中SQL Server只能在Windows平台下使用;Oracle、MySQL、DB2等可以在所有主流平台运行。总体上对比来说Oracle 大型、完善、安全;SQL Server简单,界面友好,是Windows平台下比较好的选择;MySQL免费,功能不错,适合个人网站及一些企业的网站应用;DB2 超大型,与Oracle类似。
2. SQL Server中哪个数据类型存储数据最大?
varchar只能支持8KB个字符;TEXT数据类型用于存储大量文本数据,其容量理论上为1 到2的31次方-1(2 147 483 647)个字节;NTEXT数据类型与TEXT类型相似,不同的是NTEXT类型采用UNICODE 标准字符集(Character Set), 因此其理论容量为2 30 -1(1 073 741 823)个字节;IMAGE 数据类型用于存储大量的二进制数据Binary Data,其理论容量为2 31 -1(2 147 483 647)个字节,存储数据的模式与TEXT 数据类型相同,通常用来存储图形等对象。
7.9 实战练习
在SQL Server 2008中,实现以下操作。
1. 新建1个名为JWGL(教务管理)的数据库。
2. 创建三个数据表,Student(sno,sname,age,sex);Course(cno,cname,credit);SC(sno,cno,score)。
3. 写出查询所有同学的学号、姓名、课程名、成绩的sql语句。
4. 创建一个存储过程,查询平均成绩大于60分的同学的学号和平均成绩。