6.1.5 数据通信的差错控制
差错控制是在数字通信中利用编码方法对传输中产生的差错进行控制,以提高数字消息传输的准确性。该小节主要涉及差错类型、差错控制方式、常见的检错和纠错编码。
1.差错类型和差错控制方式
通信过程中的差错大致可分为两类:一类是由热噪声引起的随机错误,另一类是由冲突噪声引起的突发错误。突发性错误影响局部,而随机性错误影响全局。而差错控制方式则会利用到不同的检错和纠错编码。
(1)差错类型
数据通信要求信息传输具有高度的可靠性,即要求误码率足够低。然而,数据信号在传输过程中不可避免会发生差错。造成误码的原因很多,主要有两个方面:一是信道不理想造成的符号间干扰,二是噪声对信号的干扰。由于信道不理想可以通过均衡办法予以改善以至消除,因此,信号噪声就成为造成传输差错的主要原因。差错控制是针对这一主要原因而采取的技术措施。
差错控制的根本措施是采用抗干扰编码,或称为检错/纠错编码。它的基本思想是通过对信息序列作某种变换,使原来彼此独立、互不相关的信息码元变成具有一定的相关性、一定规律的数据序列,从而在接收端可以根据这种规律性检查错误(检错)或进而纠正(纠错)码元在信道传输中所造成的差错。采用不同的变换方法也就构成了不同的纠错编码。
噪声的类型不同,引起的差错类型也不同,一般可分为以下两类差错。
·随机差错:差错是相互独立、互不相关的。
·突发差错:指成串出现的错码。错码与错码之间有相关性,一个差错往往会影响到后面一串字符。
在实际的信道上也可能同时存在两种类型的差错。
在差错控制技术中,编码的设计与差错控制方式的选择都与差错类型有关,因此要根据差错的类型设计编码方案以及选择适宜的控制方式。
(2)差错控制的基本方式
数据通信系统中,利用纠错编码进行差错控制的方式主要有以下4种。
1)前向纠错
前向纠错又称为自动纠错(Forward Error Correction,FEC),是发送端采用某种在解码时就能纠正一定程度传输差错的,较复杂的编码方法,该方法使接收端在收到的信码中不仅能发现错码,还能够纠正错码。采用前向纠错方式时,不需要反馈信道,也无需反复重发而延误传输时间,对实时传输有利,但是纠错设备比较复杂。
2)检错重发
检错重发又称为自动反馈重发(Automatic Repeat Request,ARQ),这种方式在是发送端采用某种能在一定程度发现传输差错的简单编码方法。该发放对所传信息进行编码,加入少量监督码元。在接收端则根据编码规则对收到的编码信号进行检查,一旦检测出(发现)有错码时,即向发送端发出询问的信号,要求重发。发送端收到询问信号时,立即重发已发生传输差错的那部分信息,直到正确收到为止。发现差错是指在若干接收码元中知道有一个或一些是错的,但不一定知道差错的准确位置。
3)反馈校验
反馈校验是发送端不进行纠错编码,接收端收到信息码后不管有无差错一律通过反向信道反馈到发送端,在发送端与原信息码比较,如有差错则将有差错的部分重发。这种方式的优点是不需要插入监督码,设备简单;主要缺点是实时性差,需要反馈信道。
4)混合纠错
混合纠错的方式是少量纠错在接收端自动纠正;差错情况较严重,超出自行纠正能力时,就向发送端发出询问信号,要求重发。因此,“混合纠错”是“前向纠错”和“反馈纠错”两种方式的混合。
对于不同类型的信道,应采用不同的差错控制技术。
2.检错和纠错编码
合法码字占所有码字的比率就是编码效率。码距是衡量一种编码方式的抗错误能力的一个指标。数字信息在传输和存取的过程中,由于各种意外情况的发生,数据可能会发生错误,即所谓误码。
一种编码,如果所有可能的码字都是合法码字,例如,美国信息交换标准代码(American Standard Code for Information Interchange,ASCII),当码字中的一位发生错误时,这个错误的码仍然在编码体系中,这样,称这种编码的码距小。如果把编码体系变得稀疏一点,使得很多的信号值不在编码体系之内,这样,合法的码字如果出现错误,可能就变成了不合法的编码,这样的编码的码距就变大了。
一个编码系统中任意两个合法的编码之间的不同的二进制位叫这两个码字的码距。该编码系统的任意两个编码之间的距离的最小值称为该编码系统的码距。
显然,码距越大,编码系统的抗偶然错误能力越强,甚至可以纠错。同时,码距的增加,使得必须提供更多的空间来存放码字,数据冗余增加,编码效率则降低了。系统设计师需要综合考虑系统效率和系统健壮性两个方面,在众多的编码体系中选择适合特定目标系统的编码。
常见的检错纠错码奇偶校验码、行列监督码、汉明码、恒比码、循环冗余校验(Cyclical Redundancy Check,CRC)。
(1)奇偶监督码
奇偶校验较为简单,被广泛地采用,常见的串口通信中基本上使用奇偶校验作为数据校验的方法。
一个码距为1的编码系统加上一位奇偶校验码后,码距就成为2。产生奇偶校验时将信息数据的各位进行模二加法,直接使用这个加法的结果作为校验码的称为奇校验。把这个加法值取反后作为校验码的称为偶校验。从直观的角度而言,奇校验的规则是:信息数据中各位中1的个数为奇数,校验码为0,否则校验码为1。偶校验则相反。
使用1位奇偶校验的方法能够检测出一位错误,但无法判断是哪一位出错。当发生两位同时出错的情况时,奇偶校验也无法检测出来。所以奇偶校验通常用于对少量数据的校验,如一个字节。在串口通信中,通常是一个字节带上起始位、结束位和校验位共11位来传送。
如果对一位奇偶校验进行扩充,在若干个带有奇偶校验码的生数据之后,再附上一个纵向的奇偶校验数据,如表6-6所示。
表6-6 奇偶校验
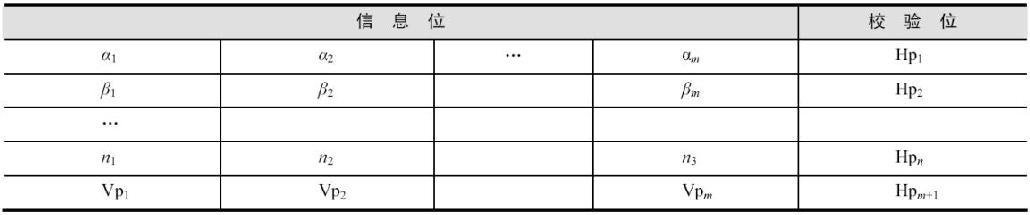
这样,在出现一个错误的情况下,就能找到这个错误。而如果出现两个以上的错误,则可能无法判断误码的位置。这种校验方式在移动通信中被广泛采用。
(2)行列监督码
行列监督码是二维的奇偶监督码,又称为矩阵码,这种码可以克服奇偶监督码不能发现偶数个差错的缺点,并且是一种用以纠正突发差错的简单纠正编码。
其基本原理与简单的奇偶监督码相似,不同的是每个码元要受到纵和横的两次监督。因此,矩阵码发现错码的能力是十分强的。
(3)汉明码
汉明码属于线性分组编码方式,大多数分组码属于线性编码,其基本原理是,使信息码元与监督码元通过线性方程式联系起来。线性编码建立在代数学群论的基础上,各许用码组的集合构成代数学中的群,故又称为群码。
(4)循环冗余校验码
这种方式已经被广泛地在网络通信及磁盘存储时采用。
在循环冗余校验码中,无一例外地要提到多项式的概念。一个二进制数可以以一个多项式来表示。如1011表示为多项式x3 +x1 +x0 ,在这里,x并不表示未知数这个概念,如果把这里的x替换为2,这个多项式的值就是该数的值。从这个转换可以看出多项式最高幂次为n,则转换为二进制数有n+1位。
编码的组成是由循环冗余校验码校验由K位信息码加上R位的校验码。
由K位信息码生成R位的校验码的关键在于生成多项式。这个多项式是编码方和解码方共同约定的,编码方将信息码的多项式除以生成多项式,将得到的余数多项式作为校验码;解码方将收到的信息除生成多项式,如果余数为0,则认为没有错误,如果不为0,余数则作为确定错误位置的依据。
生成多项式并非任意指定,它必须满足最高位和最低位为1,数据发生错误时余数不为0,对余数补0后继续做按位除,余数循环出现,这也是冗余循环校验中循环一词的来源。
校验码的生成步骤如下。
①将K位数据C(x)左移R位,给校验位留下空间,得到移位后的多项式C(x)xR 。
②将这移位后的信息多项式除生成多项式,得到R位的余数多项式。
③将余数作为校验码嵌入信息位左移后的空间。
例如,信息位为10100110,生成多项式为a(x)=x5 +x4 +x+1,则有如下表达式。
C(x)=x7 +x5 +x2 +x
C(x)xR =x5 (x7 +x5 +x2 +x)=x12 +x10 +x7 +x6
求余式如下。

得到余式为x4 +x3 ,即校验码为11000,所以,得到的CRC码是1010011011000。
循环冗余校验码的纠错能力取决于K值和R值。在实践中,K值往往取得非常大,远远大于R的值,提高了编码效率。在这种情况下,循环冗余校验就只能检错不能纠错。一般来说,R位生成多项式可检测出所有双位错、奇数位错和突发错位小于或等于R的突发错误。使用循环冗余校验码能用很少的校验码检测出大多数的错误,检错能力是非常强的,这是它得到了广泛应用的原因。